検索と置換ワイルドカード大研究
初めに
ワイルドカードはトランプのジョーカーと同じで、任意の文字に置き換えることができる
特殊な半角文字([ ] { } < > ( ) - @ ? ! * \ ^)のことです。
[検索と置換]ダイアログボックスの[オプション]ボタンをクリックしますと、画面が下側に展開されます。
□ワイルドカードを使用する
このチェックボックスをクリックしてチェックを入れますと、
画面下側にある[特殊文字]ボタンをクリックすることが出来ます。
その特殊文字のリストからワイルドカードを挿入することが出来ます。
ワイルドカードはこの様に定義しています。
範囲 ranges
[ ], [ - ]
集団 groups
()
反復 repeats
@, {}, {-}, ()\1
固定 anchors
< >
除外 exceptions
!
これらを組み合わせ、検索する文字の並びをパターン化することで、
いろいろな検索条件を作ることが出来ます。
そして、置換後の文字列で、語順を並べ替えたり、表示をしないことで、
削除したり、ある文字を追加したりすることが出来ます。
つまり、意味では無く、無機的な文字や記号の並びのパターンを
ワイルドカードを使って表すことです。
法則
|
1. |
?
と * ? は、1文字のみ s?t は、 sat, set, sit, sat および全ての “s” で始まり “t” で終わる文字の並びの組み合わせを検索します。 s*t は、上記の他、 “secret”, “serpent”, “sailing boat” など単語だけでなく、 “sign over document”,のように文字列も検索されてしまいますので、要注意です。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2. |
@ @ は、直前の文字が1つまたは、反復して続いている文字並びを検索します。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3. |
<
> このタグ < >
はそれぞれ文字並びの始めと終わりに使用します。 使用例として “*” を使い、 <s*t>
は、、“secret” 、 “serpent” 、 “sailing boat” を検索しますが、 また、 <s*t> は文章において、最初がsで始まり、単語の最後がtで終わるところまでの文章を詮索してしまいますので、注意が必要です。 通常、 <> は上記の様にセットで使用しますが、単独でも使用できます。 ful@>
は、 “full” や単語の一部の “wilful” を検索します。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4. |
[ ]
と[ - ] 常に角カッコはセットで使用します。 指定した文字そのもの、指定した文字の内の1文字を検索します。 また。半角のハイフン(-)を使って、 指定した文字コードの並びの範囲内の1文字を検索します。 [abc] は、 a, b, c. [A-Z] は、全ての英大文字 コード体系:日本語シフト JIS(16進数)より それぞれの文字コードの最初と最後を挿入したものです。 [ヲ-゚]は、半角カタカナ [ァ-ヶ]は、全角カタカナ(長音「ー」は検索されません) [ぁ-ん]は、全角ひらがな(長音「ー」は検索されません) [亜-黑]は、漢字 ※英数字のすべてを検索対象とする場合、 [\!-∟] 検索する文字列の範囲を[記号と特殊文字]の並びの順番の範囲を指定します。 [記号と特殊文字]ダイアログボックスを開き、 [フォント]欄の右側枠で▼をクリックし、 [(英数字用のフォント)]にします。 ↓ そうしますと、最初は空白で、2番目が「!」、 グループの最後はWord2000、2003では「fl」、Word2007では「∟」になっています。 Word2000、2003では、「無限大∞」の次に、「∟」があります。 この2番目の「!」はワイルドカードに使用されている特殊文字ですので(次項を参照)、 これを通常のリテラル文字として認識させるには、その前に、半角の円記号「\」を付けます。 たとえば、英数字のすべてを フォント:Times New Roman サイズ:12pt に変更をしたい時、 検索する文字列 [\!-∟] (範囲内の任意の1文字) 置換後の文字列 ^& (検索する文字) そして、カーソルを置換後の文字列の枠内に置いたまま、 左下隅の [書式▼]ボタンをクリックし、 リストから [フォント]をクリック、 ダイアログボックス内で、 [英数字用のフォント]をTimes New Roman [フォントサイズ]を12pt を指定します。 参考画面はこちら +++ いかなる文字やスペースまたは、文字コード表の一連の範囲の文字を [ ] 内で指定することが出来ます。 範囲内の1文字は、文字コード表の若い番号の順に指定する必要があります。 文字コード表は、[記号と特殊文字]のコード表の順番を参照して下さい。 [ ] で囲んで、半角のセミコロン : または、半角の縦線 | で、区切ります。 区切るのは、カッコ始めとカッコ終わり 例えば、以下のようなカッコ群 (文字列) [文字列] 「文字列」 《文字列》 <文字列> などを削除して、カッコ内の文字列だけにするには、 検索する文字列 全角のカッコの場合: [(;)] 半角のカッコの場合: [\(;^)] 置換後の文字列には、何も入力しません。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
5. |
\ [ ] { } < > ( ) - @ ? ! *
\ は、ワイルドカードとして認識されるメタ文字です。 検索の対象として、これらのメタ文字(特殊文字)をリテラル文字(通常文字)とする必要がある場合には、\をその前に付けます。 [\?] は、“\” ではなく、 “?” を検索します。 [\\].は、“\” を検索します。 単に\を付けるよりも、正確を期すため、角カッコ[ ]で括る方が良いでしょう。 特に、置換後の文字列の枠内で、¥に置換する場合は、[\\].よりも、後述の^92を使用する方が間違えありません。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6. |
[!]と[! - ] [!] は、[ ] と良く似ていますが、指定した文字以外を検索します。 [!o] は、“o”以外(を除く)の全てのアルファベットを検索します。 [!A-Z] は、大文字以外(を除く)の全ての文字を検索します。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
7. |
{ }と{ , } {数字n}は、直前の文字が連続して並んでいる個数nを指定します。 a{2} は、 “aa” を検索します。 {数字n,} は、直前の文字の連続して並んでいる個数nの下限を指定します。 a{2,} は、 “aa” や “aaaa”. などを検索します。 {数字n, 数字m} は、直前の文字の連続して並んでいる個数の下限の個数nと上限の個数mを指定します。 a{2,3} は、 “aa” と “aaa” を検索します。しかし、 “aaaa” では、最初の3文字のみが検索されます。 尚、上限の個数mを省略することが出来ます。その場合は最大個数の255個を指定したことになります。 ちなみに、カンマの後ろ側の上限値に256を入力して、検索をしますと、 検索が出来ない旨の注意ダイアログが表示されます。 なぜ、255個かと言いますと、多分16進数の総個数が0~255個の256個で、 0は無いので、255となるのではないでしょうか。 直前の文字を範囲指定した場合、 [deno]{4} は、 done, node, eden が検索されます。 (ts, ){3} は、 ts, ts, tsが検索されます。 また、連続個数でゼロ(0)は指定できませんので、[!^13]{0,} は機能しません。 使用例: 数字がいろいろあり、 1200 100 1100
1235100 221002 3100 この内、100 だけを検索したい場合、 <[1][0]{2}> となります。 最初は1で始まり、最後は0が2つ並んで終わっている文字並びのパターンを作ることで、 100だけの検索が可能になる訳です。 ※重要 このパターンを活用することが、ワイルドカードを活用することだと考えて下さい。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
8. |
( ) ( ) は、文字並びを一つの集合体(グループ)として指定します。 その一塊りの優先順位(語順)が指定されます。 左から順に第一順位、第二順位…となります。 そして、[置換後の文字列]の枠内で、\1 \2 を使用してそのグループの語順を並べ替えることが出来ます。 (John) (Smith) は、 \2 \1 で、 Smith John と並べ替えが出来ます。 また、単に \2 とすれば、 Smith.だけに置き換えることが出来ます。 ※重要1 尚、[検索する文字列]の枠内でも Fred Fred を (Fred) \1 と記述することが出来ます。 日本語の畳語(ジュウコ)と同じです。 畳語(ジュウコ)の例は、 名詞(代名詞)では、家家(家々)、我我(我々)、各各(各々)、これこれ、段段(段々)、一つ一つ 皆皆(皆々)、峰峰(峰々)、村村(村々)、山山(山々)等 副詞では、様々、次々、多々、少々、遅々、早々(そうそう、脈々、切々、燦々(さんさん)、時々、 営々(えいえい)、往々(おうおう)、度々(たびたび)、更々、寒々、丸々、黙々、赤々、青々、黒々、 努々(ゆめゆめ)、またまた、もっともっと、いろいろ、うすうす、うずうず、まざまざ、みすみす等があります。 このように漢字では、々(おなじ)を重複する文字として使用しています。 (連続、反復を指定できます。後述の使用例も参照して下さい。) ( ) は色々な場面で活用出来る大変便利なワイルドカードです。 ※重要2 \1で置換することも基本中の基本です。 このパターンを活用することも、ワイルドカードを活用する基本だと考えて下さい。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
9. |
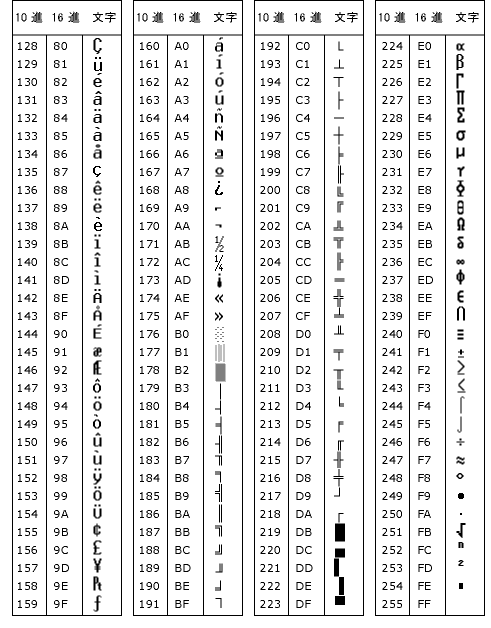
^ ^ (“キャレットまたは、ハット”) は、ワイルドカードを使用しない通常の検索で、特殊文字のリストから段落記号を選択しますと、[検索する文字列]の枠内には^p と表示されます。 このように、^+アルファベットまたは、記号で検索する文字や置換後の文字で使用されます。 ところが、ワイルドカードを使用するにチェックを入れますと、段落記号はリストにはありません。そこで、^+文字コードの組み合わせで検索するようになります。 段落記号のワイルドカードは^13です。これは単なる文字コードに過ぎませんので、 置換後の文字列の枠内にこれを使って置換をしますと、段落記号はそのままですが、 文字扱いになり、正常な段落記号の働き(書式の保持など)が無くなってしまいます。 [置換後の文字列]の枠内で段落記号を使う時には、必ず^pを使わなければならないことに注意して下さい。 +++ この不具合についての検証 by んなっと さん 下の いい┛ に段落スタイル[赤、斜体など]が設定されて (※貴重な検証を引用させて頂きました。有難うございます。) +++ また、[置換後の文字列]の枠内では、半角の円記号(\)は、上記の様に、 語順の置き換えに使われますので、^92 を使う様にして下さい。 以下は文字コード表とワイルドカードの一覧です。 (記号と特殊文字で、[英語数字用のフォント]にし、コード体系をASCII10進数に しますと、これらのコード文字の一部を見ることができます。) ASCII文字コード表とワイルドカード
ASCII 文字コード表 128~255
16×16=256 ^0~^255で、256個になります。 この256個はパソコンの制限値(仕様)に良く出てくる数値です。 16進数に関係していると思います。 参考事項 ASCII 文字 を検索するには、 「^nnn」と入力します。nnn は文字コードです。 つまり、^000 ~ ^255 の256件のことです。 ANSI 文字 「^0nnn」と入力します。0 はゼロ、nnn は文字コードです。 [ワイルドカードを使用する] チェック ボックスがオフのときに [検索する文字列] ボックスでのみ入力できるコード 任意の文字 「^?」と入力します。 任意の数字 「^#」と入力します。 任意の英字 「^$」と入力します。 Unicode の文字 「^Unnnn」と入力します。nnnn は文字コードです。 |
使用例
英語の敬称 ("Mr.", "Mrs.", "Dr.") には、米国ではピリオドが付きますが、英国では付きません。
そこで、ワイルドカードを使ってピリオドを取ったり、付け足したりするには、
ピリオドを付け足す場合
検索する文字列: ([DM][rs]{1,2})( )
置換後の文字列: \1.\2
([DM][rs]{1,2})( ) の意味は、
Mr Mrs Dr の各々の後ろには空白スペースがある(ピリオドが付いていない)文字並びを検索するワイルドカードの命令です。
[DM] は、[ ] の中に、DMを入力したものです。
[ ]は、その角カッコの中で
「指定した文字のいずれか一文字」
を検索します。
ですから、DまたはMのいずれか一文字を検索します。(Mr、Mrs,Dr の最初の大文字)
同様に、[rs]はrまたはsのいずれか一文字を検索します。
ところが、その後に{1,2}が付いています。
{1,2}の意味は、{a,b}が基本型で、直前に指定した文字の並びの個数を限定することが出来ます。
aは、下限の個数(これ以上)を表し、
bは、上限の個数(これ迄)を表します。
つまり、[rs]{1,2}はrまたはsのいずれか一文字が1個以上、2個迄並んでいる文字並びを検索します。
つまり、6種類(r, s, rr, ss, rs, sr)の文字並び(組み合せ)が検索対象となります。
([DM][rs]{1,2})( ) のように( ) ( ) で囲んでいますが、
後ろのカッコ内には、半角スペースが入力されています。
この( ) ( ) は、検索の文字並びの一塊りの優先順位を表し、
左から順に第一順位、第二順位…となります。
置換後の文字列: \1.\2
この意味は、検索された第一順位の文字並びと、第二順位の半角スペースの間に半角ピリオドを入れた文字並びに変更しなさいという命令になります。
また逆に、半角ピリオドを取るには、
検索する文字列:([DM][rs]{1,2}).
置換後の文字列:\1
とすれば、第一順位の文字並びだけとなり、結果的にピリオドが削除されることになります。
使用例
[検索する文字列]:(*^13)\1
[置換後の文字列]:\1
これは、文書の中の重複し連続している段落記号を全て削除します。
置換の残りの個数が0になるまで、置換を繰り返します。
また、この操作は表の空白行を削除する際にも利用できます。つまり、一旦表をタブ区切りで、
解除し、必要のない段落を削除してから、再度表に変換をすれば良いことになります。
または、
([^13])@
\1
または、
^13{2,}
^p
の様に、3つの方法があります。
使用例
入れ替え
(<*>)[空白](<*>)
\2[空白]\1
使用例
西暦の年月日の入れ替え
([0-9]{1,2}[dhnrst]{2})[空白](<[AFJMNSOD]*>)[
空白]([0-9]{4})
\2[空白]\1,[ 空白]\3
その他
3桁区切りを検索と置換で自動変換する方法
3桁区切りの別方法
検索と置換で一気に見出しスタイルを設定する方法
検索と置換で空の段落記号(←┘)を一括削除する方法
検索と置換の基本事項あれこれ
検索と置換で▲を右向き▲に置換する方法
検索で半角カタカナを全角に変換する方法
「 」とその中の文字を削除したい
空白行をなくすことはできますか
¥に置き換えたい
半角\円記号の検索と置換について
すべての文字列の前後にある文字をつけたい
手入力したアウトライン番号の変更
脚注番号をカッコで括る方法
漢字:都道府県のみをカッコで括るには
図(画像)に図表番号を一括で挿入するには
図表番号の太字スタイルを解除するには
縦書き文書で半角英字小文字を縦中横に一括置換
半角のスペースだけを一括削除するには
その他(このサイトに提示しているトピックス)
ワイルドカードとコードの一覧
3-3-1ルビ解除の際に使用するワイルドカードの参考資料
8.負の数値(-マイナスが数値の冒頭にある)を赤色で表示する方法
![]()