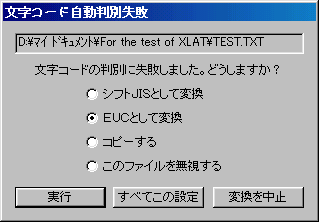
「文字コード判定失敗」エラーの説明
入力ファイルの文字コードを自動判別できないとき、このエラーが発生します。「シフトJISで、半角カナだけで構成され、各行が全て偶数文字の文章」や「EUCで仮名の前半ばかりの文章」など、かなり中身の偏った文章でないと、このエラーは発生しないはずです。
実行を続けるときは、文字コードを指定してやるか、無視するか、コピーするかの選択を行い、「実行」もしくは「すべてこの設定」ボタンを押します。
以下に、各項目の説明を行います。
元ファイルの文字コードが分かっている場合は、ここで手動で指定してやれば、その文字コードだとして変換します。
このタイミングで元ファイルを確認して、文字コードがなんなのかをブラウザかメモ帳などで確認するとよいでしょう。
このファイルを出力先にコピーします。
出力先のフォルダを指定せず、「ファイルを直に変換し、元ファイルを残さない」という設定を行っている際には選択できません。
このファイルを無視し、次のファイルの変換作業に移行します。
ここで選択した設定を適用し、変換作業を続行します。
ここで選択した設定を、今回の変換作業の全てに適用します。これ以降の変換においてこのエラーが発生しても、ここでの設定を自動的に適用します。
次回の変換作業からは、またこのエラーダイアログが表示されるようになります。次回というのは再起動したときという意味ではありません。
今回の変換作業全体を中止します。