翻訳作業に関する備忘録
(1) 原文の電子テクストの入手
今は、とても簡単になりましたね。テクストの入手先は、私の場合、次のようなところで検索してみました。
英語以外の単語が混在したり、イタリック体が使われたりしている可能性を考えると、プレーンのテクストファイル(*.txt)よりも、書式設定を含んだファイルがよいと思います。
ワードのファイル(*.doc, *.docx)
リッチテキストファイル(*.rtf)
HTMLファイル(*.htm, *.html)
PDFファイル(*.pdf)
電子テクストが手に入らない場合は、翻訳対象の本を全部コピーしたり、裁断してPDFに読む込んだりする(いわゆる「自炊」をする)ことになります。公開されているPDFでも、スキャンしただけの自炊ファイルと同レベルのものがあります(PDFビューワーで【検索可能なファイルに変換しますか?】といったお知らせが出る)。このような場合は、変換の際に文字化けや変換ミスが出て煩雑な修正作業が必要になることもあります。とはいえ、ミスの少ない高品質の翻訳をめざすのであれば、十分に報われる作業だと思います。
扱うのが英文ばかりで慣れていないせいで、ギリシャ文字、フランス語のアクサンとかドイツ語のウムラートを電子テクストで扱うのを面倒に感じてきました。でも、面倒がって先延ばしていると、精神が老け込んでしまいそうで、よくありません。「人生という仕事とは、前進することである (The business of life is to go forward.)」ということですね。
そこで、試しに、ルソー『社会契約論』のPDF版・ワード版・HTML版のそれぞれを、ネット検索してダウロードしてみました。ワード版(*.docxや*.rtf)では、文章をコピーしてエクセルに貼り付けてみると、アクサンもイタリックもきちんと再現できました。というわけで、ここで開拓した方法は、英語以外にも使えそうです。
【この段階での作業のゴール】
書式や独仏文字などが保存されたワードファイル(必要ならば章ごとに分割したもの)を作る。
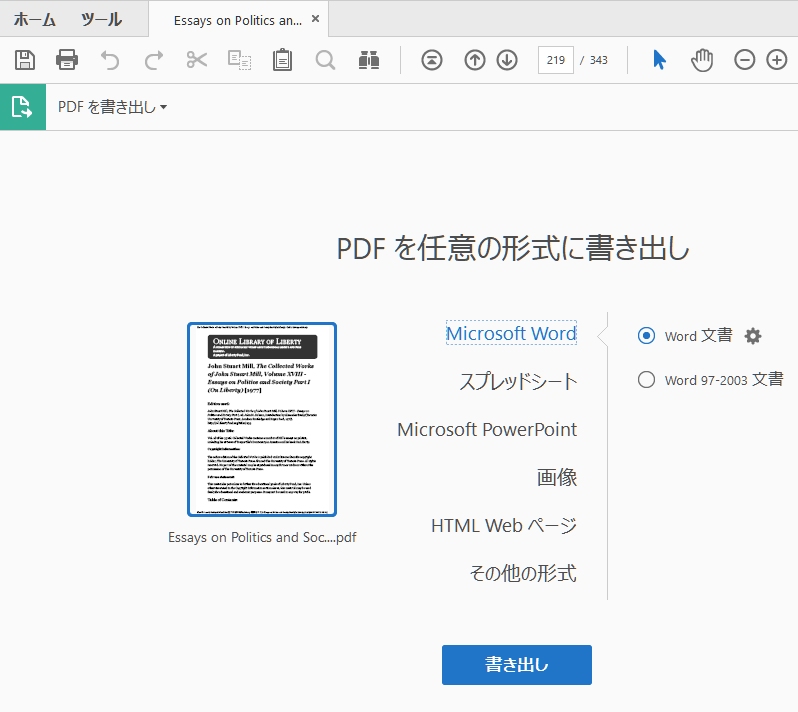
HTMLファイル → PDFファイル → ワードファイル

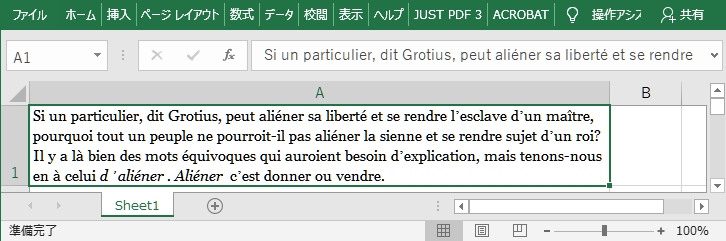
ワード上では、下のようになります。
(イタリック体、フランス語、ドイツ語、ラテン語、ギリシャ語の表示例)

→(2)に続く