シンプルなCPUを作ってみよう (その5)
-パイプライン処理の導入-
井澤 裕司
1.はじめに
CPUを高速化する手法のひとつに,「 パイプライン処理 」があります.
本章では,これまで設計してきたCPUに,この「 パイプライン処理 」を導入した例を紹介します.
2.パイプライン処理による高速化
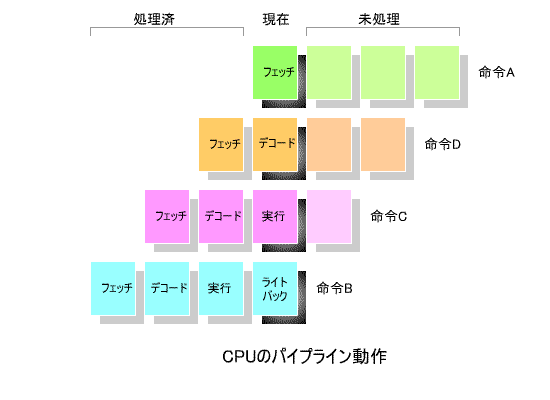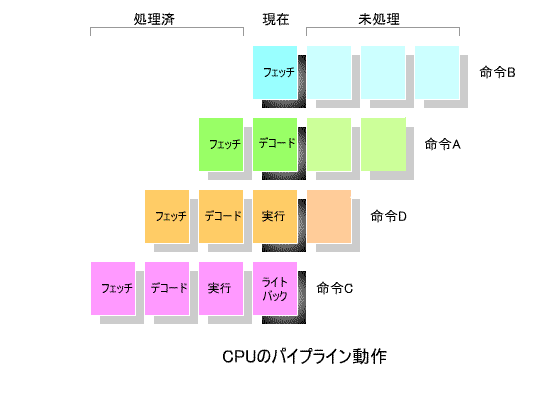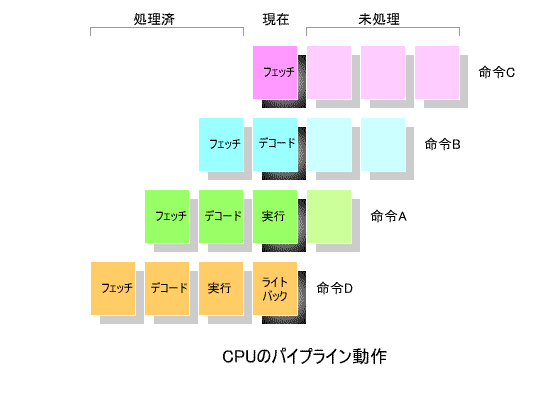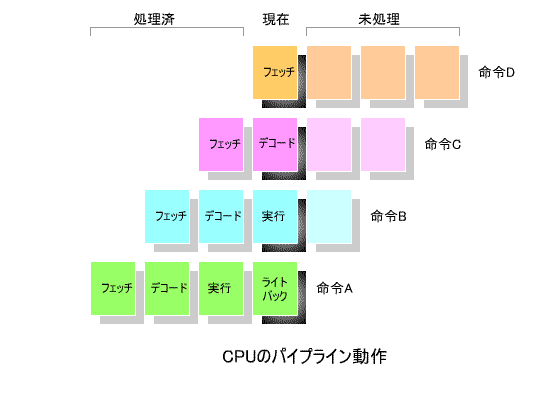
下の図は,CPUの「 パイプライン処理 」の概念を表しています.
この「 パイプライン処理 」は,ベルトコンベアによる 分業作業 に例えることができます.
すなわち, ①フェッチ , ②デコード , ③実行 , ④ライトバック の4つの作業を,4人の作業員がそれぞれ分担し,
流れ作業で処理する方式です.
すべての処理を1人で行う場合に比べ,作業効率は 最高4倍 まで向上します.
3.パイプラインハザードとリソース(資源)の競合
3.1 パイプライン・ハザードとは
ベルトコンベアによる組み立て作業を導入することにより,効率は大幅に改善されますが,
問題が全くないわけではありません.
例えば,不良部品が混入している場合,ベルトコンベアを一旦停止させ,正常な部品に交換した後,
ベルトコンベアを再び起動します.
最悪の場合,ベルトコンベアの上を整理し,最初からやり直す必要があります.
CPUの処理も同様で, Jump 等の命令により, ①フェッチ , ②デコード , ③実行 , ④ライトバック の4つの作業の
流れに乱れが生じます.
このような乱れを, パイプライン・ハザード (あるいは パイプライン・ストール )と呼びます.
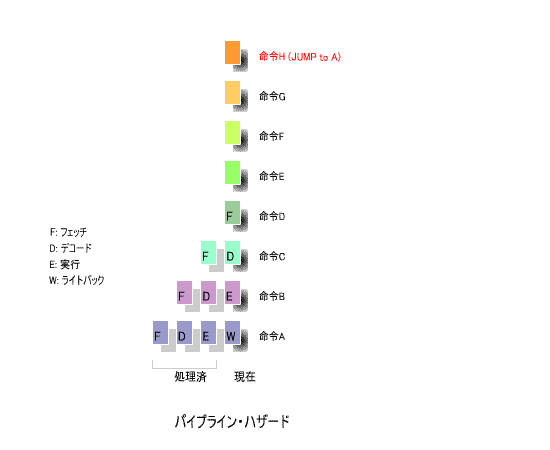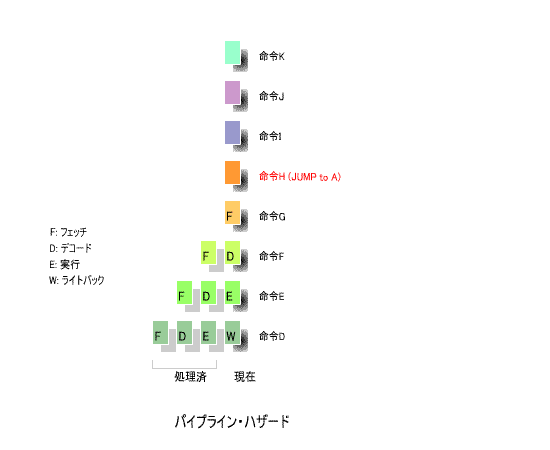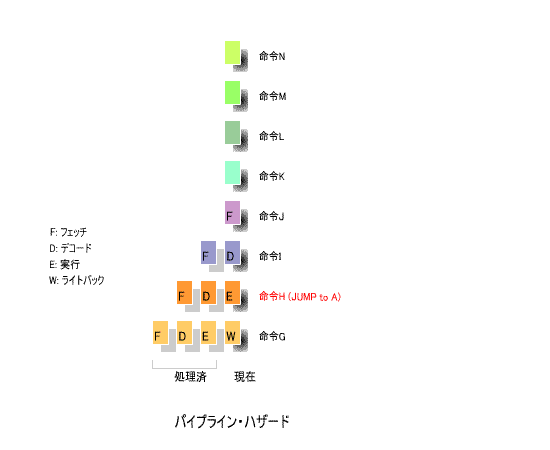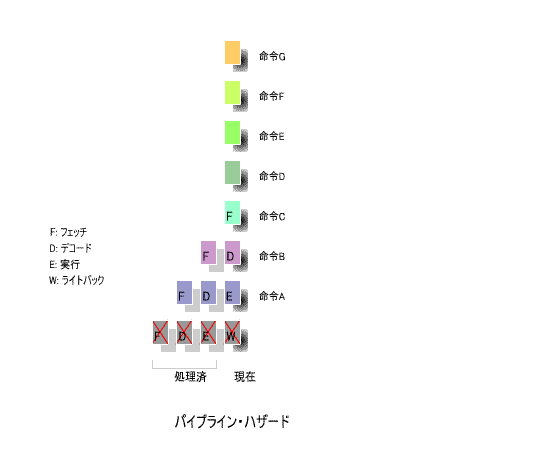
下の図を用いて, パイプライン・ハザード の概念を説明しましょう.
例えば Jump 命令をライトバックのフェーズで実行すると,指定されたアドレスにプログラムカウンタ(PC)が
セットされます.
その時点で, Jump 命令に続く次の命令がそれぞれ, フェッチ , デコード , 実行 の作業を完了しているわけで,
これをそのまま実行すると,計算結果に 誤り が生じます.
このため,一旦白紙の状態に戻し, Jump 先の命令から,再度 ①フェッチ , ②デコード , ③実行 , ④ライトバック の
処理を行う必要があります.
3.2 リソース(資源)の競合とは
Jump 命令の実行時でなくても, パイプライン・ハザード が生じることがあります.
リソース(資源)の競合による パイプライン・ハザード です.
例えば,組み立て作業でボルトを締め付けるスパナが1つしかない場合,2つの締め付け作業を同時に
行うことは不可能です.
スパナであれば2セット用意することにより解決しますが,データを保存するレジスタやメモリの場合,
正しいデータが読み込まれない状況が生じます.
データが書き込まれるのは,④のライトバックのフェーズであり,データを読み込むのは②のデコードの
フェーズです.この間に2クロックの時間のずれがあります.
例えば,[ レジスタ 0 ]の値" 2 "に" 10 "を加算した直後に[ レジスタ 0 ]を読み出す場合について考えてみましょう.
第4章までの設計手法では,データを書き込んだ後で読み出すので,"12"という値が得られます.
ところが,パイプライン処理を導入すると,上記の時間のずれにより,書き込む前の[ レジスタ 0 ]の値" 2 "が
読み出され,正しい結果が得られません.
このようなパイプライン・ハザードを防ぐ最も簡単な方法は,プログラミング上の工夫によるものです.
次節では,その方法を紹介します.
4.プログラミングの工夫
パイプライン・ハザードを避ける最も簡単な方法は, Jump 等の命令の後や資源が競合する命令コードの間に,
何もしない命令( NOP 命令 )を必要なクロックの数だけ挿入することです.
これにより,CPUの動作に無駄が生じ,処理の効率は低下します.
しかし,もともと RISC型のCPU は,命令を極力単純化することにより,動作クロックの周波数を上げて,
処理の回数で全体的な性能能力を改善しようとする考え方に基づいて,開発されてきました.
一般のプログラムの場合, Jump 等の命令の頻度はそれほど多くなく, NOP 命令 の挿入による
性能の低下はそれほど大きいものではありません.
パイプライン処理の導入に伴い,プログラミングを以下のように訂正する必要があります.
以下に,具体的なプログラムのソースコードを示します.
赤いコードが,挿入した NOP 命令です.
なお,従来の手法では,プログラムカウンタ(PC)を更新しない hlt 命令により,
CPUを停止させることができました.
しかし,今回採用したパイプライン処理では,この hlt 命令は使えません.
hlt 命令の実行では, その後に続く同じ命令(例えば nop )が2度フェッチされるだけで,プログラムカウンタが更新
され続けるからです.
このため,下のプログラミングの例では,自分のアドレスにジャンプする jmp 命令を用いて,実質的にCPUを停止させています.
prom2.vhd
-- magafunction wizard: %LPM_ROM%
-- GENERATION: STANDARD
-- VERSION: WM1.0
-- MODULE: lpm_rom
-- (略)
0: ldl Reg0 0 -- Reg0 ← 0 1: ldl Reg1 1 -- Reg1 ← 1 2: ldl Reg2 0 -- Reg2 ← 0 3: ldl Reg3 10 -- Reg3 ← 10 4: nop -- リソースの競合を防ぐため 5: add Reg2 Reg1 -- Reg2 ← Reg2 + Reg1 6: nop -- リソースの競合を防ぐため 7: nop -- リソースの競合を防ぐため 8: add Reg0 Reg2 -- Reg0 ← Reg0 + Reg2 9: cmp Reg2 Reg3 -- Reg2 と Reg1 の比較 10: je 16 -- 一致したら 16番地に Jump 11: nop -- パイプライン・ハザードを防ぐため 12: nop -- パイプライン・ハザードを防ぐため 13: jmp 5 -- 無条件に 5番地に Jump 14: nop -- パイプライン・ハザードを防ぐため 15: nop -- パイプライン・ハザードを防ぐため 16: st Reg0 64 -- RAMの 64番地に Reg0の内容を出力 17: jmp 17 -- Jump命令によるCPUの停止(無条件に 17番地に Jump) 18: nop -- 19: nop --
architecture SYN of prom2 is signal sub_wire0 : std_logic_vector(14 downto 0); compnent lpm_rom GENERIC ( intended_device_family : string; (略) lpm_type : string; ) ; port ( outclock : in std_logic ; address : in std_logic_vector( 4 downto 0); inclock : in std_logic ; q : out std_logic_vector(14 downto 0) ); end compnent ;
begin q <= sub_wire0(14 downto 0); lpm_rom_component : lpm_rom GENERIC MAP ( intended_device_familt => "FLEX10KE" , lpm_width => 15, lpm_widthad => 5 , lpm_address_control => "REGISTERED" , lpm_outdata => "REGISTERED" , lpm_file => "prom.mif" , lpm_type => "LPM_ROM" ) port_map ( outclock => outclock, address => address, inclock => inclock, q => sub_wire0 ); end SYN;
-- CNX file retrival info
-- (略)
ROMの記述に,外部のmifファイルを用いる場合は,以下のように修正します.
-- prom2.mif
-- 15bit RISC processor
-- cpu15pipe.vhd用
-- Y.Izawa
-- H18.5.8
depth = 32;
width = 15;
address_radix = HEX;
data_radix = BIN;
content begin [00..1F] : 000000000000000 ; 00 : 100000000000000 ; -- ldl Reg0 0 01 : 100000100000001 ; -- ldl Reg1 1 02 : 100001000000000 ; -- ldl Reg2 0 03 : 100001100001010 ; -- ldl Reg3 10 04 : 000000000000000 ; -- nop 05 : 000101000100000 ; -- add Reg2 Reg1 06 : 000000000000000 ; -- nop 07 : 000000000000000 ; -- nop 08 : 000100001000000 ; -- add Reg0 Reg2 09 : 101001001100000 ; -- cmp Reg2 Reg3 0A : 101100000010000 ; -- je 16 0B : 000000000000000 ; -- nop 0C : 000000000000000 ; -- nop 0D : 110000000000101 ; -- jmp 5 0E : 000000000000000 ; -- nop 0F : 000000000000000 ; -- nop 10 : 111000001000000 ; -- st Reg0 64 11 : 110000000010001 ; -- jmp 17 12 : 000000000000000 ; -- nop 13 : 000000000000000 ; -- nop 14 : 000000000000000 ; -- nop 15 : 000000000000000 ; -- nop 16 : 000000000000000 ; -- nop 17 : 000000000000000 ; -- nop 18 : 000000000000000 ; -- nop 19 : 000000000000000 ; -- nop 1A : 000000000000000 ; -- nop 1B : 000000000000000 ; -- nop 1C : 000000000000000 ; -- nop 1D : 000000000000000 ; -- nop 1E : 000000000000000 ; -- nop 1F : 000000000000000 ; -- nop end ;
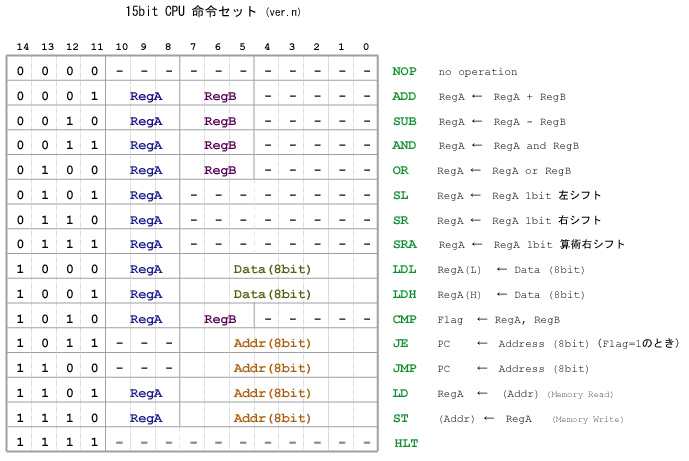
5. 命令セットの修正
パイプライン処理を実現するためには,一部の命令セットを修正する必要があります.
具体的には,これまで レジスタ間データのコピー” MOV ”に対応する命令を,何もしない ” NOP ”命令に変更します.
以下に,修正した命令セットを示します.
VHDLのソースコードは以下のように修正します.
赤で示す部分が修正箇所です.exec2.vhd
-- exec2.vhd
-- Y.Izawa
-- H18.4.25
library IEEE;
use IEEE.std_logic_1164.all;
use IEEE.std_logic_unsigned.all;
entity exec2 is port ( CLK : in std_logic ; RESET : in std_logic; OP_CODE : in std_logic_vector (3 downto 0); PC_IN : in std_logic_vector (7 downto 0); REG_A : in std_logic_vector (15 downto 0); REG_B : in std_logic_vector (15 downto 0); OP_DATA : in std_logic_vector (7 downto 0); RAM_OUT : in std_logic _vector (15 downto 0); PC_OUT : out std_logic_vector (7 downto 0); REG_IN : out std_logic_vector (15 downto 0); RAM_IN : out std_logic_vector (15 downto 0); REG_WEN : out std_logic; RAM_WEN : out std_logic ); end exec2; architecture RTL of exec2 is
signal CMP_FLAG : std_logic;
begin process (CLK, RESET) begin if (RESET = '1') then PC_OUT <= "00000000"; elsif (CLK'event and CLK = '1') then case OP_CODE is when "0000" => -- NOP REG_WEN <= ' 0 '; RAM_WEN <= ' 0 '; PC_OUT <= PC_IN + 1; when "0001" => -- ADD REG_IN <= REG_A + REG_B; REG_WEN <= '1'; REG_WEN <= '0'; PC_OUT <= PC_IN + 1; when "0010" => -- SUB (略) when "1111 " => when others => end case ; end if ; end process ; end RTL;
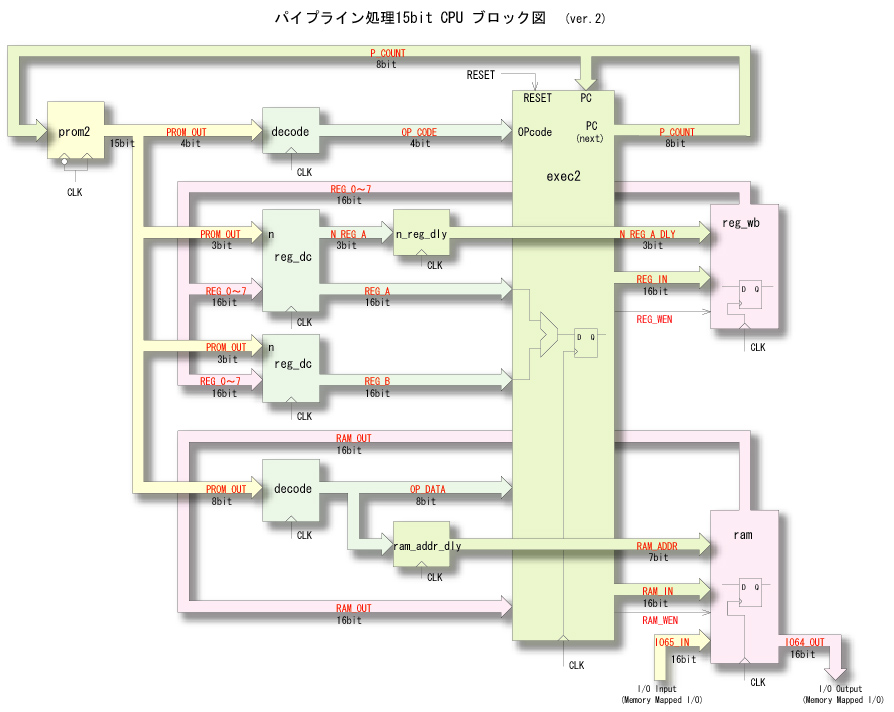
6. タイミング設計の修正
パイプライン処理を導入するためには,タイミング系の設計も修正する必要があります.
具体的には,ライトバックフェーズにおけるレジスタの番号と,RAMのアドレスが,デコードの
タイミングで生成されているため,1クロック分遅延させる必要があります.
この時間調整は,実行フェーズのクロックで,上記信号をラッチする処理に等価です.
これにより,それぞれの命令が,同じ位相で同時並行処理されるようになります.
パイプライン処理を行うCPUのブロック図を,以下に示します.
主な変更箇所は,
①レジスタの番号 (N_REG)
②RAMのアドレス (RAM_ADDR)
を1クロック遅延させる回路 (n_reg_dly.vhd,ram_addr_dly.vhd) を追加した点です.
以下,それらのコンポーネントのソースコードを示します.
6.1 n_reg_dly.vhd
-- n_reg_dly.vhd
-- Y.Izawa
-- H18.4.24
library IEEE;
use IEEE.std_logic_1164.all;
entity n_reg_dly is port ( CLK : in std_logic; DIN : in std_logic_vector (2 downto 0); QOUT : out std_logic_vector (2 downto 0) ); end n_reg_dly;
architecture RTL of n_reg_dly is
begin process (CLK) begin if (CLK'event and CLK = '1') then QOUT <= DIN ; end if ; end process ; end RTL;
6.2 ram_addr_dly.vhd
-- ram_addr_dly.vhd
-- Y.Izawa
-- H18.4.24
library IEEE;
use IEEE.std_logic_1164.all;
entity ram_addr_dly is port ( CLK : in std_logic; ADDR_IN : in std_logic_vector (7 downto 0); ADDR_OUT : out std_logic_vector (7 downto 0) ); end ram_addr_dly;
architecture RTL of ram_addr_dly is
begin process (CLK) begin if (CLK'event and CLK = '1') then ADDR_OUT <= ADDR_IN ; end if ; end process ; end RTL;
7. パイプライン処理のCPU
パイプライン処理を用いたCPUのソースコードは以下のようになります.
赤で示したコードが修正した部分です.
すべてのコンポーネントが,基本クロックCLKで動作している点に注意して下さい.
パイプライン処理によるCPUのソースコード(cpu15pipe.vhd)
-- cpu15pipe.vhd
-- Y.Izawa
-- H18.4.24
library IEEE;
use IEEE.std_logic_1164.all;
use IEEE.std_logic_unsigned.all;
entity cpu15pipe is
port
(CLK : in std_logic; RESET : in std_logic; IO65_IN : in std_logic_vector (15 downto 0); IO64_OUT : out std_logic_vector (15 downto 0) ); end cpu15pipe;
architecture RTL of cpu15pipe is
component prom2 (略) end component;
component decode (略) end component;
component reg_dc (略) end component;
component exec2 (略) end component;
component n_reg_dly (略) end component;
component ram_addr_dly (略) end component;
component reg_wb (略) end component
component ram port
(CLK : in std_logic; RAM_WEN : in std_logic ; ADDR : in std_logic_vector (6 downto 0); DATA_IN : in std_logic _vector (15 downto 0); DATA_OUT : out std_logic_vector (15 downto 0); IO65_IN : in std_logic_vector (15 downto 0); IO64_OUT : out std_logic_vector (15 downto 0) ); end component;
signal P_COUNT : std_logic_vector (7 downto 0); signal PROM_OUT : std_logic_vector (14 downto 0); signal OP_CODE : std_logic_vector (3 downto 0); signal OP_DATA : std_logic_vector (7 downto 0); signal N_REG_A : std_logic_vector (2 downto 0); signal N_REG_B : std_logic_vector (2 downto 0); signal N_REG_A_DLY : std_logic_vector (2 downto 0); signal REG_IN : std_logic_vector (15 downto 0); signal REG_A : std_logic_vector (15 downto 0); signal REG_B : std_logic_vector (15 downto 0); signal REG_WEN : std_logic; signal REG_0 : std_logic_vector (15 downto 0); signal REG_1 : std_logic_vector (15 downto 0); signal REG_2 : std_logic_vector (15 downto 0); signal REG_3 : std_logic_vector (15 downto 0); signal REG_4 : std_logic_vector (15 downto 0); signal REG_5 : std_logic_vector (15 downto 0); signal REG_6 : std_logic_vector (15 downto 0); signal REG_7 : std_logic_vector (15 downto 0); signal RAM_IN : std_logic_vector (15 downto 0); signal RAM_ADDR : std_logic_vector (7 downto 0); signal RAM_OUT : std_logic_vector (15 downto 0); signal RAM_WEN : std_logic ;
begin C1 : prom2 port map ( P_COUNT (4 downto 0), not CLK, CLK, PROM_OUT); C2 : decode port map ( CLK , PROM_OUT, OP_CODE, OP_DATA); C3 : reg_dc port map ( CLK , REG_0, REG_1, REG_2, REG_3, REG_4, REG_5, REG_6, REG_7, PROM_OUT(10 downto 8), N_REG_A, REG_A); C4 : reg_dc port map ( CLK , REG_0, REG_1, REG_2, REG_3, REG_4, REG_5, REG_6, REG_7, PROM_OUT(7 downto 5), N_REG_B, REG_B); C5 : exec2 port map ( CLK , RESET, OP_CODE, P_COUNT, REG_A, REG_B, OP_DATA, RAM_OUT, P_COUNT, REG_IN, RAM_IN, REG_WEN, RAM_WEN); C6 : n_reg_dly port map (CLK, N_REG_A, N_REG_A_DLY); C7 : ram_addr_dly port map (CLK, OP_DATA, RAM_ADDR); C8 : reg_wb port map ( CLK , N_REG_A_DLY , REG_IN, REG_WEN, REG_0, REG_1, REG_2, REG_3, REG_4, REG_5, REG_6, REG_7); C9 : ram port map ( CLK , RAM_WEN, RAM_ADDR(6 downto 0) , RAM_IN, RAM_OUT, IO65_IN, IO64_OUT); end RTL;
8. まとめ
このコンテンツでは,パイプライン処理を導入したシンプルなCPUの設計法について解説しました.
誤りや分かり難い点について,率直に指摘していただけると有難いです.
また,不明な点は遠慮なく質問して下さい.