
シンプルなCPUを作ってみよう (その1)
- C言語によるCPUシミュレータの制作 -
井澤 裕司
1. はじめに
ここでは、極めてシンプルな構成のCPUを ハードウェア記述言語を用いて設計し,FPGAという半導体
デバイスへ実装して動作させる方法について解説します.
具体的には,
① 極めて単純な15bitの命令セットをもつRISC型のオリジナル・プロセッサ(CPU)を
② ハードウェア記述言語( VHDL )を用いて設計し,
③ FPGA (Field Programmable Gate Array)という半導体デバイスを用いて実際に動作させます.
これまでの設計手法とは大きく異なり,はじめにソフトウェア(C言語)を用いて「 CPUシミュレータ 」を作成します.
次に,そのソースコードを修正して,ハードウェア記述言語(VHDL)へと発展させます.
このコンテンツは,以下の構成になっています.
本章では,C言語を用いて「 CPUシミュレータ 」を制作します.
第1章(その1) C言語によるCPUシミュレータの制作 第2章(その2) VHDLを用いた全体設計 第3章(その3) VHDLを用いたコンポーネントの設計 第4章(その4) より実用的なCPUを目指して 第5章(その5) パイプライン処理の導入 第6章(その6) C言語によるクロスアセンブラの制作
CPUやアセンブリ言語に習熟している場合は,本章を読み飛ばし第2章に進んでも結構です.
しかし,アセンブリ言語を用いたプログラミングや,その開発環境(クロスアセンブラ)に関連する内容が
含まれており,オリジナルプロセッサのアセンブリ言語を開発する際のデバッグツールとしても活用できます.
プログラミング作業やそのデバッグに,かなりの時間や労力を要するかもしれませんが,
これらの作業を通して,CPUの基本的な構成や動作が,具体的にイメージできるようになり,
目的地にいち早く到達することができるでしょう.
「 コンピュータアーキテクチャ 」の復習にもなりますので,しっかり学習して下さい.
2. 設計手法について
比較的単純なプロセッサの設計手法は,ハードウェア記述言語(HDL)関連の書籍で数多く紹介されています.
また,具体的な設計例についても,大学の授業や研究室のレベルで数多く報告されています.
これらは,概ね以下のような手順により設計されています.
(1) CPUのアーキテクチャを決定し,命令セット(演算bit数やレジスタ数),基本的なタイムチャート等を設計する.
(2) 算術演算回路(ALU)や,レジスタ,制御回路(シーケンサ)等を,回路図あるいはハードウェア記述言語( HDL )
を用いて具体化する.
(3) 机上検討やHDLのシミュレータ等によりデバッグを行い, FPGA に実装して動作を確認する.
これらはオーソドックスかつ効率的な手法ではありますが,CPUのハードウェア(演算回路)から,
簡単なソフトウェア(マシン語やアセンブリ言語)に関する幅広い知識が要求されるため,
初心者には,ハードルの高いものとなっています.
一方,C言語やJava等のソフトウェアは広く普及しており,情報工学を学ぶほとんどすべての学生は,
これらを自由に使いこなすことができます.
ここでは,このような方を対象に,以下のような設計方法を用いることにします.
(1) CPUのアーキテクチャを決定し, 命令セット (演算bit数やレジスタ数)を設計する.
(2) 上記アーキテクチャの動作をシミュレートする「 CPUシミュレータ 」を,C言語を用いて制作する.
(3) 基本的なタイムチャート等を作成し,具体的な制御方法を設計する.
(4) 算術演算回路(ALU)や,レジスタ,制御回路(シーケンサ)等を,ハードウェア記述言語(HDL)を用いて
具体化する.
(5) (2)で作成した「 CPUシミュレータ 」や,HDLの開発環境のシミュレータ等を用いてデバッグを行い,
FPGAにより動作確認する.
手順の(2) が通常の設計手法とは大きく異なる部分です.
このCPUシミュレータの制作に,かなりの労力と時間をかけています.
CPUの具体的な動作や演算回路,マシン語,アセンブリ言語等について,復習する必要があるかもしれません.
しかしながら,このCPUシミュレータを用いて,簡単な計算を行うプログラムをアセンブリ言語を用いて
記述できる頃には,CPUの具体的な動作もイメージできるようになり,最終的なゴールに早く到達することが
可能になるでしょう.
一方,(2)で作成したC言語のデコード (Decode) や実行 (Execute) の部分は,比較的簡単にVHDLに置き換えること
が可能です.
なお,「 CPUの動作原理 」や「 演算回路 」,「 VHDLによる回路設計 」等について,もう一度復習する必要があるでしょう.
これらについては,例えば以下のような資料がありますので,参考にして下さい。
(1) 論理回路1 (組合せ回路)
http://www7b.biglobe.ne.jp/~yizawa/logic/index.html
(2) 論理回路2 (順序回路およびハードウェア記述言語)
http://www7b.biglobe.ne.jp/~yizawa/logic2/index.html
(3) コンピュータアーキテクチャ資料 (CPUの構成やアセンブリ言語)
http://www7b.biglobe.ne.jp/~yizawa/CompArch/index.htm
それでは,CPUの設計を始めましょう.
3. CPU命令セットの設計
最も簡単なCPUの例として,15bitの 固定命令長 をもつ RISC型プロセッサ を設計します.
今回の設計では,次の表に示す 命令セット を用いることにします.
なお, 演算レジスタ長 はきりのよい 16bit とします.
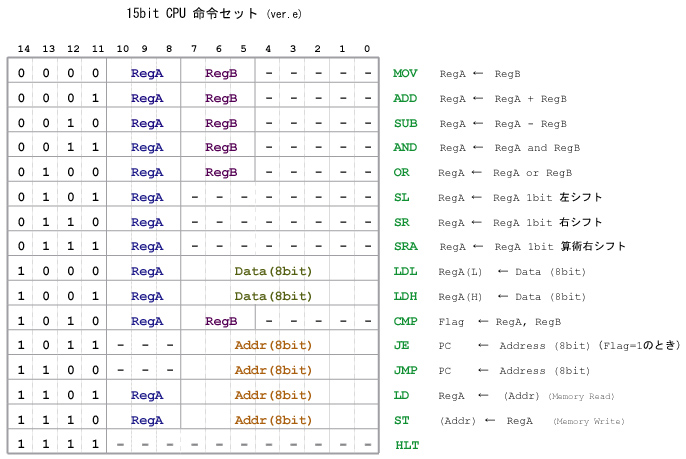
以下,簡単に補足しましょう.
上位のbitの4ビット bit[14~11] は,命令コード( OP Code )に対応します.
したがって,命令の数は以下に示す16種類となります.
0 0000 MOV Move レジスタ間のデータコピー 1 0001 ADD Addition 加算 2 0010 SUB Subtraction 減算 3 0011 AND Logical And 論理積 4 0100 OR Logical Or 論理和 5 0101 SL Shift Left (1bit) 左シフト (1bit) 6 0110 SR Shift Right (1bit) 右シフト (1bit) 7 0111 SRA Shift Right Arithmetic (1bit) 右算術演算シフト (1bit) 8 1000 LDL Load Immediate Low 即値ロード(Low) 9 1001 LDH Load Immediate High 即値ロード(High) 10 1010 CMP Compare 比較 11 1011 JE Conditional Jump (Equal) 条件付ジャンプ 12 1100 JMP Jump ジャンプ 13 1101 LD Load Memory メモリからの読み込み 14 1110 ST Store Memory メモリへの書き込み 15 1111 HLT Halt 停止
さらに 1bit 追加して 16bit とし,命令数を倍に増やしたいところですが,
設計の簡略化のため今回は 15bit に抑えています.
また,条件付きジャンプ ( JE ) では, bit[10~8] の 3bit を活用すれば,不等号 (>)のような
条件をいくつか追加することも可能ですが,今回は採用しません.
表にない命令は,16種類の命令を複数組み合わせることにより,実現します.
この考え方は, RISC型CPU の基本方針に沿ったものです.
オペランドは 2アドレス方式 とします.
すなわち,2つのソースレジスタ( Source Register ) RegA と RegB があり,それらの演算結果が
デスティネーション・レジスタ( Destination Register ) RegA に書き込まれます.
レジスタA ( RegA ) には bit[10~8] の3ビット,レジスタB ( RegB ) には bit[7~5] の3 ビットを割り当てます.
レジスタ RegA , RegB の数はともに 8種類ありますが,実際のレジスタ( Reg )は8個しか存在しないことに
注意して下さい.
アドレッシングも簡略化し,絶対アドレスのみ用いることにします.
すなわち,分岐( Jump )やメモリアドレスは,8bit の絶対的な番地で指定します.
8bitのメモリサイズでは実用的なプログラミングは不可能という意見もあるでしょう.
そのような用途に備え,第4章でメモリの拡張方法について補足します.
今回は,回路の単純化のため,命令コード(プログラム)のバスと,データ用のバスを分離した
「ハーバードアーキテクチャ」 を採用します.
なお,プログラムメモリ( PROM )の内容は,説明の簡略化のためVHDLの中で記述しています.
次の段階で,外部ファイルから読み込む方式に置き換えることは比較的簡単です.
また,データメモリのサイズも小さいので,今回はレジスタで実現することにしました.
入出力(I/O)を,メモリマップトI/O( Memory Mapped I/O )で構成するため,レジスタによる構成は好都合です.
4. アセンブリ言語によるCPUのプログラミング
上の命令セットを理解するためには,実際にアセンブリ言語を用いて簡単なプログラムを作るのが有効です.
ここでは,以下のような計算をしましょう.
1 + 2 + 3 + ‥+ 10 = 55
この 計算は,アセンブリ言語を用いて,例えば次のようにプログラミングすることができます.
0: ldl Reg0 0 // Reg0(L) に 値 0 をセット 1: ldl Reg1 1 // Reg1(L) に 値 1 をセット 2: ldl Reg2 0 // Reg2(L) に 値 0 をセット 3: ldl Reg3 10 // Reg3(L) に 値 10 をセット 4: add Reg2 Reg1 // Reg2 と Reg1 の和を Reg2 に上書き 5: add Reg0 Reg2 // Reg0 と Reg2 の和を Reg0 に上書き 6: cmp Reg2 Reg3 // Reg2 と Reg3 を比較し,一致したら flag = 1 7: je 9 // flag = 1 のとき 9番地に jump 8: jmp 4 // 4番地に無条件 jump 9: st Reg0 64 // RAM の 64番地に Reg0 の内容を出力 10: hlt // CPUの停止
なお,簡単化のため,レジスタの上位 8bit はすべて 0 にクリアされているものとします.
必要に応じ,最初に "ldh Reg0 0" , "ldh Reg1 0" , "ldh Reg2 0" , "ldh Reg3 0" を
追加してください.
この動作を,次に示す JavaScript のアニメーションにより確認しましょう.
Reset ボタンをクリックすると, CPU が0番地から動作します.
とくに,4つのレジスタおよびプログラムカウンタの値,条件付き Jump の動作に注意して下さい.
5. プロセッサ(CPU)のブロック構成とその動作
これまで説明してきたプロセッサ のブロック構成を,下の図に示します.
RESETボタンをクリックすると,前節で示した計算 (1 + 2+ 3 + ‥+10 = 55 ) のプロセスがアニメーションで
表示されます.
プロセッサのハードウェア構成や,信号の流れを突然示されても理解できないのは当然です.
詳細については次章以降で説明しますので,細部にこだわらなくて結構です.
特に,図の左側のソフトウェアと右側のハードウェアの相互関係に注目して眺めて下さい.
マウスの左ボタンで,CPUの動作を停止させることが可能ですので,各部の動作の概要を理解してください.
これらの関係が理解でき, 実際の動作がイメージできるようになれば,目的のプロセッサは半ば完成した
と考えてよいでしょう.
6. C言語によるCPUシミュレータの制作
それでは,「CPUシミュレータ」の制作を始めましょう.
これまでに説明してきたプロセッサについて,アセンブルから実行までのすべての過程をC言語を用いて記述します.
以下に示すソースコードは,その一例です.
そのままコンパイルしても動作しますが,その程度では勉強になったとしても,ハードウェア化( VHDL化 )には
役立ちません.
あくまで参考程度に留め,オリジナルのシミュレータを作成することが重要です.
独自の命令セットを新規に設計し,そのシミュレータを制作することをお勧めします.
それらのプログラムのデバッグの過程で, CPU の各部の動作に関する理解が深まり,ハードウェア化への道筋が
明らかになるでしょう.
[CPUシミュレータの例]
// processorb5.c
// Simulator of 15bit processor
// H18.3.14
// Y.Izawa
#include <stdio.h> #include <stdlib.h> /* OP Codes */
#define MOV 0 #define ADD 1 #define SUB 2 #define AND 3 #define OR 4 #define SL 5 #define SR 6 #define SRA 7 #define LDL 8 #define LDH 9 #define CMP 10 #define JE 11 #define JMP 12 #define LD 13 #define ST 14 #define HLT 15
/* Registers */
#define REG0 0 #define REG1 1 #define REG2 2 #define REG3 3 #define REG4 4 #define REG5 5 #define REG6 6 #define REG7 7
short reg[8]; unsigned short rom[256]; unsigned short ram[256]; void program( void ) ; unsigned short mov(unsigned char ra, unsigned char rb); unsigned short add( unsigned char ra, unsigned char rb); unsigned short sub( unsigned char ra, unsigned char rb); unsigned short and( unsigned char ra, unsigned char rb); unsigned short or( unsigned char ra, unsigned char rb); unsigned short sl( unsigned char ra); unsigned short sr( unsigned char ra); unsigned short sra( unsigned char ra); unsigned short ldl( unsigned char ra, unsigned char data); unsigned short ldh( unsigned char ra, unsigned char data); unsigned short cmp( unsigned char ra, unsigned char rb); unsigned short je( unsigned char addr); unsigned short jmp( unsigned char addr); unsigned short ld( unsigned char ra, unsigned char addr); unsigned short st( unsigned char ra, unsigned char addr); unsigned short hlt( void );
unsigned short opcode( unsigned short ir); unsigned short nRegA( unsigned short ir); unsigned short nRegB( unsigned short ir); unsigned short op_data( unsigned short ir); unsigned short op_addr( unsigned short ir); void main( void )
{
// Registers and Flag
unsigned short pc; // Program Counter unsigned short ir; // Instruction Register unsigned short flag_eq; // Flag for Compare
// Programming
program();
// Boot of Processor
pc = 0;
flag_eq = 0;
do{ir = rom[pc];// getchar();
printf("PC:%3d IR:%4x REG0:%3d REG1:%3d REG2:%3d REG3:%3d\n"
, pc, ir, reg[0], reg[1], reg[2], reg[3]);
pc++;
// Decode and Execute
switch (opcode(ir)){
case MOV
:
reg[nRegA(ir)] = reg[nRegB(ir)];
break ;case ADD
:
reg[nRegA(ir)] = reg[nRegA(ir)] + reg[nRegB(ir)];
break ;case SUB
:
reg[nRegA(ir)] = reg[nRegA(ir)] - reg[nRegB(ir)];
break ;case AND
:
reg[nRegA(ir)] = reg[nRegA(ir)] & reg[nRegB(ir)];
break ;case OR
:
reg[nRegA(ir)] = reg[nRegA(ir)] | reg[nRegB(ir)];
break ;case SL
:
reg[nRegA(ir)] = reg[nRegA(ir)] << 1;
break ;case SR
:
reg[nRegA(ir)] = reg[nRegA(ir)] >> 1;
break ;case SRA
:
reg[nRegA(ir)] = (reg[nRegA(ir)] & 0x8000) | (reg[nRegA(ir)] >>1);
break ;case LDL
:
reg[nRegA(ir)] = (reg[nRegA(ir)] & 0xff00) | (op_data(ir) & 0x00ff);
break ;case LDH
:
reg[nRegA(ir)] = (op_data(ir) << 8) | (reg[nRegA(ir)] & 0x00ff);
break ;case CMP
:
if (reg[nRegA(ir)] == reg[nRegB(ir)]) flag_eq = 1;
else flag_eq = 0;
break ;case JE
:
if (flag_eq == 1) pc = op_addr(ir);
break ;case JMP :
pc = op_addr(ir);
break ;case LD
:
reg[nRegA(ir)] = ram[op_addr(ir)];
break ;case ST
:
ram[op_addr(ir)] = reg[nRegA(ir)];
break ;default : break ; }} while (opcode(ir) != HLT);// Output (Memory Mapped I/O)
printf("\n");
printf("CPU Simulator Results\n");
printf("ram[64] = %d\n", ram[64]);
getchar();}
// Data of Program ROM
// Exam1: 1 + 2 + ... + 10 = 55
void program( void )
{
}
rom[0] = ldl(REG0, 0); // Reg0 <- 0 rom[1] = ldl(REG1, 1); // Reg1 <- 1 rom[2] = ldl(REG2, 0); // Reg2 <- 0 rom[3] = ldl(REG3, 10); // Reg3 <- 10 rom[4] = add(REG2, REG1); // Reg2 <- Reg2 + Reg1 rom[5] = add(REG0, REG2); // Reg0 <- Reg0 + Reg2 rom[6] = cmp(REG2, REG3); // Reg2 と Reg3(10) の比較 rom[7] = je(9); // 一致したら9番地にjump rom[8] = jmp(4); // 4番地にjump rom[9] = st(REG0, 64); // OUT(64) <- Reg0 rom[10] = hlt(); // hlt
unsigned short mov( unsigned char ra , unsigned char rb )
{
return (MOV << 11) | (( unsigned short )ra << 8) | (( unsigned short )rb << 5);
}
unsigned short add( unsigned char ra, unsigned char rb)
{
return (ADD << 11) | (( unsigned short )ra << 8) | (( unsigned short )rb << 5);
}
unsigned short sub( unsigned char ra, unsigned char rb)
{
return (SUB << 11) | (( unsigned short )ra << 8) | (( unsigned short) rb << 5);
}
unsigned short and( unsigned char ra, unsigned char rb)
{
return (AND << 11) | (( unsigned short )ra << 8) | (( unsigned short )rb << 5);
}
unsigned short or( unsigned char ra, unsigned char rb)
{
return (OR << 11) | (( unsigned short )ra << 8) | (( unsigned short )rb << 5);
}
unsigned short sl( unsigned char ra)
{
return (SL << 11) | (( unsigned short )ra << 8);
}
unsigned short sr( unsigned char ra)
{
return (SR << 11) | (( unsigned short )ra << 8);
}
unsigned short sra( unsigned char ra)
{
return (SRA << 11) | (( unsigned short )ra << 8);
}
unsigned short ldl( unsigned char ra, unsigned char data)
{
return (LDL << 11) | (( unsigned short )ra << 8) | ( unsigned short )data;
}
unsigned short ldh( unsigned char ra, unsigned char data)
{
return (LDH << 11) | (( unsigned short )ra << 8) | ( unsigned short )data;
}
unsigned short cmp(unsigned char ra, unsigned char rb)
{
return (CMP << 11) | (( unsigned short )ra << 8) | (( unsigned short )rb << 5); }
unsigned short je( unsigned char addr)
{
return (JE << 11) | ( unsigned short )addr;
}
unsigned short jmp( unsigned char addr)
{
return (JMP << 11) | ( unsigned short )addr;
}
unsigned short ld( unsigned char ra, unsigned char addr)
{
return (LD << 11) | (( unsigned short )ra << 8) | ( unsigned short )addr;
}
unsigned short st( unsigned char ra, unsigned char addr)
{
return (ST << 11) | (( unsigned short )ra << 8) | ( unsigned short )addr;
}
unsigned short hlt( void )
{
return ( unsigned short )(HLT << 11);
}
unsigned short opcode( unsigned short ir)
{
return (ir >> 11);
}
unsigned short nRegA( unsigned short ir)
{
return ((ir >> 8) & 0x0007);
}
unsigned short nRegB( unsigned short ir)
{
return ((ir >> 5) & 0x0007);
}
unsigned short op_data( unsigned short ir)
{
return (ir & 0x00ff);
}
unsigned short op_addr( unsigned short ir)
{
return (ir & 0x00ff);
}
以下,簡単にソースコードの内容について説明します.
最初の #define 文は,16種類の命令コード( OP Code )を表しています.
次の #define 文は, REG0~REG7 のレジスタの番号を表す 3bit の情報を表現しています.
8個のレジスタは,配列 reg[8] で表します.
オペランドのアドレスを 8bit に設定したことから,プログラムを格納するROMを,256個の16bit 整数に
対応する配列 rom[256] で表現します.
同様に,データを格納する RAM についても,配列 ram[256] とします.
次に,命令コードに対応する関数のプロトタイプ宣言が続きます.
関数の引数が,それぞれの命令コードに用いるオペランドに対応している点に注意して下さい.
15bitの 命令セットから,4bit の命令コード,3bit のレジスタのオペランド部等を抜き出す機能も,関数を用います.
void 型の関数 program() では,1~10までの総和を計算するアセンブリ言語を,関数で模擬しています.
これにより得られた 15bitのマシン語は,配列の rom[] に書き込まれます.
次に main() 関数の内容について,説明しましょう.
はじめは, CPU の起動(ブート)です.
プログラムカウンタ pc を 0 にリセットし,比較の結果を格納する 1bit の flag を 0 クリアします.
最初にROM の 0 番地からマシン語を読み出します.
その命令コードを解読し, switch 文により,それぞれの命令コードに対応する処理を行います.
例えば,0 番地のマシン語では, " case LDL " の処理が行われます.
すなわち, REG0 の下位 8bit に,オペランドの即値データ "0" がロードされます.
通常の処理では,通常プログラムカウンタ pc が更新 (+1) されますが," jump " 関連の命令では,
オペランドのアドレス (8bit) の内容がプログラムカウンタ pc に上書きされることがあります.
これらの処理は," hlt " 命令が実行されるまで,繰り返されます.
以上の説明で,理解できましたでしょうか?
不明な点が少しでも残っている場合は,上のソースコードをもう一度注意深く読み直して下さい.
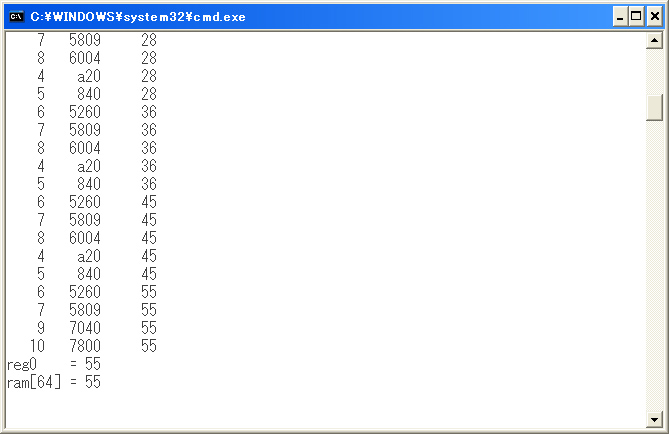
「CPUシミュレータ」を実行した結果の一例を以下に示します.
計算結果の値(55)が出力されています.
なお,上のソースコードの関数
program();
の内容を入れ替えることにより,アセンブリ言語のプログラムの作成とデバッグが可能です.
例題で用いなかった命令セットを使って,独自のプログラムを作成することをお勧めします.
また,このCPUをFPGAに実装した後,様々なプログラムを開発する場合にも,この「CPUシミュレータ」
が役に立つかもしれません.
なお,本格的な「クロスアセンブラ」の開発事例については,第6章で紹介します.
7. まとめ
例題に示した「CPUシミュレータ」の内容は,完全に理解できましたでしょうか?
また,オリジナルの命令セットによる「CPUシミュレータ」は無事動作しましたか?
この部分がしっかり理解できれば,後半のVHDLを用いた設計作業は,比較的スムーズに進むことでしょう.
シミュレータが完全に動作しない場合は,むしろチャンスと考え,その原因を究明して下さい.
また,理解が不十分と思われる場合には,ここまでの内容であいまいな点を探し出し,その部分を重点的に復習して下さい.
それが,目的に到達するための最短の道筋になることでしょう.
次章から,VHDLによる具体的なCPUの設計手法について解説します.
=>「シンプルなCPUを作ってみよう」 トップページに戻る.