
コンピュータ・アーキテクチャ [補足資料]
(CPUの高速化手法)
井澤 裕司
1. はじめに
-
ここでは、
「中央処理装置(CPU)を高速化する手法」
を中心に解説します。
-
-
分かりやすい説明を心がけたつもりですが、不明な点、あいまいな点、誤り等がありましたら、お手数ですが
-
メール等で井澤(e-mail : yizawa.cs@gmail.com)までお知らせ下さい。
-
-
本資料が有効に活用されることを願っています。
2. 高速化手法の分類
-
中央処理装置(CPU)を高速化する手法として以下のような方式があります。
-
以下、これらの内容について解説しましょう。
3.CPUの基本動作
-
まずはじめに、基本となる中央処理装置(CPU)の動作について復習します。
-
-
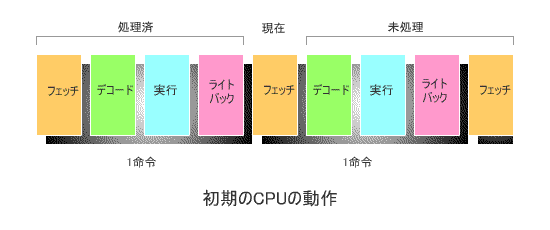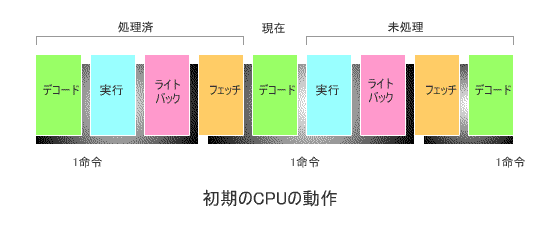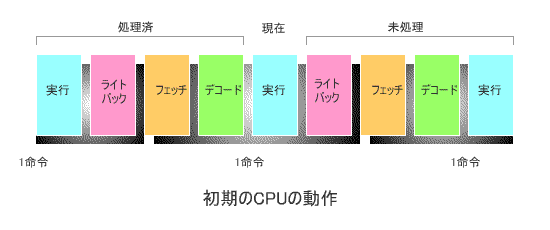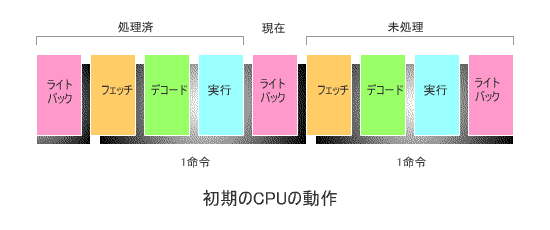
下の図は、コンピュータが開発されて間もない頃の、代表的なCPUの動作を模式的に
-
表したものです。
-
1命令の動作は4つのステージ、すなわち
-
-
(1) 命令フェッチ ; 命令コードをメモリから読み込む
-
(2) 命令デコード ; 読み込んだ命令コードを解析し、実行の準備を行う
-
(3) 実行 ; CPU内部の演算ユニットで命令を実行する
-
(4) ライトバック ; 実行結果をレジスタやメモリに書き込む
-
-
で構成させるものとしています。
-
このとき、各ステージが1クロックで実行されるとすると、1命令の実行が完了するのに
-
4クロックを要します(*)。
-
-
(*) 実際には、メモリのアドレスを計算するステージを含めて5ステージとしたり、
-
各ステージのクロック数が命令の内容によって変化する構成が用いられます。
[補足] アセンブリ言語とマシン語
-
CPUの動作をハードウェアの面から把握するためには、アセンブラ言語とマシン語(機械語)について
-
理解する必要があります。
-
これらはCPUの種類やソフトウェア開発環境により数多くの種類がありますが、ここではx86系の
-
単純なものを例に説明します。
-
-
下の図は、アセンブリ言語を用いて、整数の1から10までの総和を計算するプログラムを表しています。
-
使用するCPUのレジスタは、
ax
、
bx
、
cx
の3種類と、プログラムカウンタ(
pc
)です。
-
図の
[resetボタン]
をクリックすると、プログラムカウンタが
0
にリセットされ、
-
0番地の命令
[mov ax, 0]
から実行を開始します。
-
以下、簡単に各行の内容について説明します。
-
-
・0番地
[mov ax, 0]
; axレジスタに値0を代入する。
-
・1番地
[mov bx, 1]
; bxレジスタに値1を代入する。
-
・2番地
[mov cx, 0]
; cxレジスタに値0を代入する。
-
・3番地
[add ax, bx]
; axレジスタとbxレジスタの和を計算し、結果をaxレジスタに代入する。
-
・4番地
[inc bx]
; bxレジスタに1を加算する。
-
・5番地
[inc cx]
; cxレジスタに1を加算する。
-
・6番地
[cmp cx, 10]
; cxレジスタと値10を比較する。
-
・7番地
[jne LOOP1]
; 比較の結果、もし一致していなければ、ラベルのLOOP1(3番地)にジャンプし、
-
一致していれば次の8番地に進む。
-
・8番地
[stop]
; プログラムカウンタを止める。
-
-
なお、プログラムを読みやすくするため、3番地には
[LOOP1]
というラベルが付けられています。
-
しかし、実際のCPUでは、このような
ラベル
や
[mov]
や
[add]
のような記号(文字列)が使用されている
-
わけではなく、これらに対応する
0と1で構成されるビット列
(これを
「マシン語」
、
「機械語」
と言います)
-
をメモリから読み込んでいます。
-
-
最終的な結果として、
axレジスタ
に
55
という数値が現れます。
-
このようなCPUの動作をよく理解し、これらの動きが頭の中でイメージできるよう訓練して下さい。
[補足] CISC(Complex Instruction Set Computer) と RISC (Reduced Instruction Set Computer)
-
-
この後で説明する
キャッシュメモリ
が実用化されるまでは、主メモリからCPUにデータを
-
読み込む
「フェッチ」
のステージに最も時間を要していました。
-
CPUの高速化のためには、
「フェッチ」動作
の実質的な回数を減らすことが重要です。
-
そこで、複雑な命令でも1クロックでフェッチできる
CISC型プロセッサ
が主流になりました。
-
このCISCでは、命令コードの長さは一定ではなく、1バイト(8bit)から2バイト、あるいは
-
それ以上の長さのコードが混在するのが一般的です。
-
-
一方、メモリから高速にデータを読み込む方式が研究され、
キャッシュメモリ
という
-
手法が実用化されるようになりました。
-
このキャッシュメモリについては、別途解説するつもりですが、CPUの内部もしくは
-
その近くに、小容量ながら極めて高速に動作するSRAMを設け、主メモリから
-
バースト的にまとめてデータを読み込んでおく方式です。
-
CPUがアクセスすべき主メモリの内容と、このキャッシュメモリの内容が一致するとき、
-
このキャッシュメモリの内容を用いることにより、極めて高速な動作が可能になります。
-
内容が一致しない場合は、主メモリからこのキャッシュメモリにデータを書き込みますが、
-
CPUは確率的に比較的狭い領域内のメモリを繰り返し使用することが多いので、全体的
-
に見ると処理速度が飛躍的に向上するわけです。
-
-
この
キャッシュメモリ
の技術が導入されると、命令の
「フェッチ」
に要する時間は
-
大幅に短縮され、
「デコード」
や
「実行」
に要する時間の方が長くなってしまいました。
-
CPUの高速化のためには、
「デコード」
や
「実行」
の内容を単純化する必要があります。
-
そこで、
CISC型プロセッサ
の命令体系を根本的に見直し、必要最小限の単純な命令を
-
高速に実行する
RISC型プロセッサ
が提案され、開発されるようになりました。
-
このRISCでは、CISCのような複雑な命令は単純な命令の組み合わせにより実行します
-
また、パイプライン処理等の制御の煩雑さを避けるため、通常命令コードは一定の長さに
-
統一されています。
-
-
半導体プロセスの進歩により、キャッシュメモリの高速化、大容量化が進んだため、現在は
-
この
RISC型プロセッサ
が主流になっています。
-
4.パイプライン方式
-
上の図の「初期のCPUの動作」で示したように、代表的なCPUの動作は
「フェッチ」
、
-
「デコード」
、
「実行」
そしてレジスタやメモリに演算結果を書き込む
「ライトバック」
の
-
4ステージで構成されます。
-
-
初期のCPUでは、これらを1クロックごとに実行していたため、1つの命令に4クロック
-
必要でした。
-
1人の人間が4つの仕事を行うより、4人で手分けした方が仕事が早く進むことは明らかです。
-
そこで、ベルトコンベアを1台設置し、1人の人間が1つの仕事を担当し、これが完了したら
-
次の人にバトンタッチする
「流れ作業」
を導入します。
-
これが、
「パイプライン方式」
です。
-
-
下の図で、実際の動作を説明します。
-
命令A、B、C、Dの順序でCPUは処理を行います。
-
-
(1) 最初の1クロック目で、命令Aが「フェッチ」されます。
-
(2) 2クロック目では、命令Aが「デコード」され、これと同時に命令Bが「フェッチ」されます。
-
(3) 3クロック目では、命令Aが「実行」、命令Bが「デコード」、命令Cが「フェッチ」されます。
-
(4) 4クロック目では、命令Aが「ライトバック」、命令Bが「実行」、命令Cが「デコード」、命令Dが「フェッチ」されます
。
-
-
ここでは、4つのステージをもつパイプライン方式について説明しましたが、5ステージ以上の場合でも、
-
実質的に1命令1クロックで実現できることは明らかです。

-
それでは、質問です。
-
このような「パイプライン方式」がすべての場合に有効であるというわけではありません。
-
どのようなとき、問題が生じるのでしょうか? 考えてみて下さい。
5.
パイプライン・ハザード
-
「流れ作業」
において、各ステージの仕事の内容が一定で、同じ処理を繰り返し行う場合には、
-
問題は起きません。しかし、ベルトコンベアが一旦停止したり、不良な部品が流れてきて、
-
良品と交換しなければならない場合等には、ラインに乱れが生じます。
-
-
CPUでは、様々な命令を1クロック毎に処理しますが、例えば
「条件付きジャンプ」
などの命令は、
-
その直前に実行した比較等の命令の結果により、次の命令以外の場所にジャンプしたり、
-
ジャンプしなかったりします。
-
-
すなわち、
「パイプライン処理」
しない初期のCPUでは問題は発生しませんが、
「パイプライン処理」
-
により高速化を図るCPUでは、ラインの乱れ、すなわち
「パイプライン・ハザード」
(あるいは
「パイプライン・
-
ストール」
)が生じます。
-
-
下の図を使って、この
「パイプライン・ハザード」
について説明します。
-
-
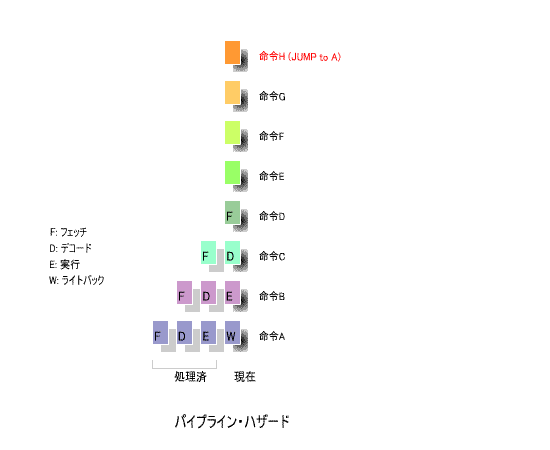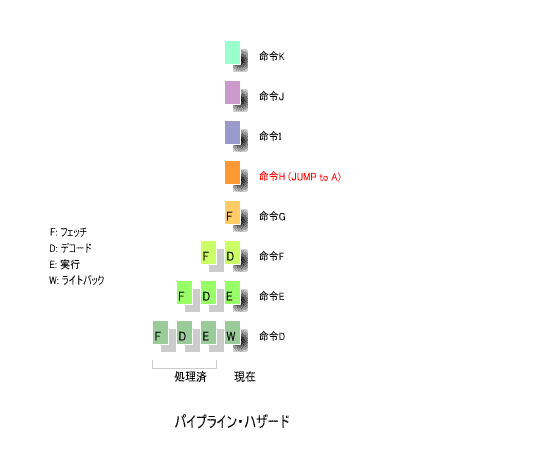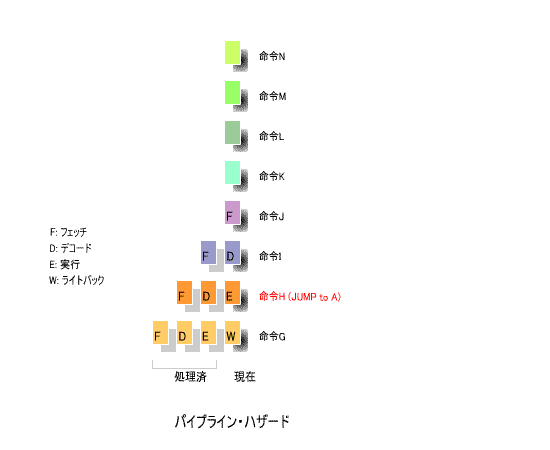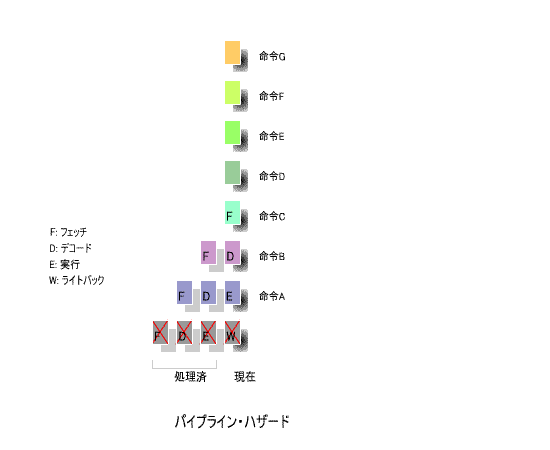
4ステージのパイプライン処理により、
命令A
、
命令B
、
命令C
、、の順に実行します。
-
命令Hがジャンプ命令であり、ジャンプする先が
命令A
のアドレスであるとします。
-
命令Hが
「実行」
のステージに達したとき、
命令I
は
「デコード」
、
命令J
は
「フェッチ」
の
-
ステージにあります。
-
したがって、ジャンプ命令の後に命令Aを実行するためには、パイプラインの途中にある
-
命令I
と
命令J
の内容をすべて消去し、命令Aを
「フェッチ」
のステージから繰り返さなければ
-
なりません。
-
なお、図の
×印
は消去すべき命令を表しています。
-
このように、ジャンプ命令を実行すると、ステージの途中にある命令を消去し、ジャンプする先の
-
命令を
「フェッチ」
から再開する操作が必要となります。
-
パイプラインの流れは、高速な処理の妨げとなります。これが
「パイプライン・ハザード」
です。
6. 分岐予測方式
-
「パイプライン・ハザード」
による処理能力の低下を解決するために考案されたのが、ここで述べる
-
「分岐予測方式」
です。
-
-
この方式は、条件付きジャンプ命令を実行する場合に、
①ジャンプしたか
、
②ジャンプしなかったか
を
-
記録する
1ビット(もしくは数ビット)のレジスタ
を設け、この命令を次に実行する場合に、このレジスタの
-
内容を参照して分岐の有無を予測し、
「パイプライン・ハザード」
を回避するものです。
-
-
一般に条件付きジャンプは、一定の条件が満たされるまでループ状に何度も繰り返すことが多いので、
-
1回目と、ループを抜ける最終回以外は、
「パイプライン・ハザード」
を回避することができるわけです。
-
-
下の図を用いて、具体的に説明しましょう。
-
これは、アセンブラ言語を用いて、整数の1から10までの総和を計算して、結果を出力ポートに出力する
-
プログラムです。先に示した例を多少変更していますので、注意してください。
-
使用するCPUのレジスタは、
ax
、
bx
の2種類と、プログラムカウンタ(
pc
)です。
-
図の
[resetボタン]
をクリックすると、プログラムカウンタが
0
にリセットされ、
-
0番地の命令
[mov ax, 0]
から実行を開始します。
-
以下、簡単に各行の内容について説明します。
-
-
・0番地
[mov ax, 0]
; axレジスタに値0を代入する。
-
・1番地
[mov bx, 0]
; bxレジスタに値0を代入する。
-
・2番地
[inc bx]
; bxレジスタに1を加算する。
-
・3番地
[add ax, bx]
; axレジスタとbxレジスタの和を計算し、結果をaxレジスタに代入する。
-
・4番地
[cmp bx, 10]
; bxレジスタと値10を比較する。
-
・5番地
[jne LOOP1]
; 比較の結果、もし一致していなければ、ラベルのLOOP1(2番地)にジャンプし、
-
一致していれば次の6番地に進む。
-
・6番地
[mov dx, PORT]
;
dxレジスタに出力するポートのアドレス(PORT)を設定する。
-
・7番地
[out dx, ax]
; dxで指定した出力ポートに、axレジスタの内容を出力する。
-
・8番地
[stop]
; プログラムカウンタを止める。
-
-
なお、条件付きジャンプ命令
[jne]
を1回目に実行するまでは、分岐予測は
[不明]
となりますが、この例では
-
[分岐あり]の方向へジャンプさせています。
-
したがって、
「パイプライン・ハザード」
が発生するのは、ループを抜ける最終回です。(bxレジスタ=10の場合)。
-
このとき、既に
「フェッチ」
、
「デコード」
を完了している2番地と3番地の結果を消去し、6番地のポート設定
-
の命令から
「フェッチ」
し直す必要があり、3クロックの間CPUが停止しているようにみえます。
-
-
このような
「分岐予測方式」
の動作をよく理解し、頭の中でイメージできるよう努力して下さい。
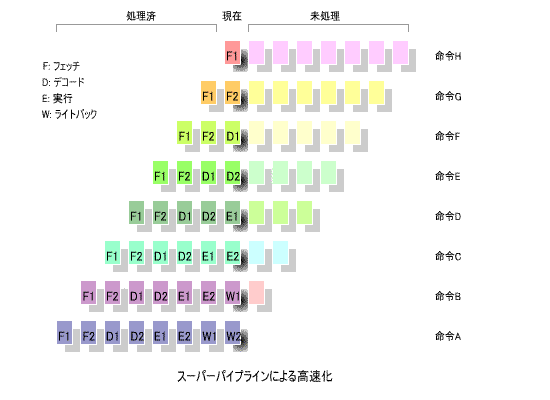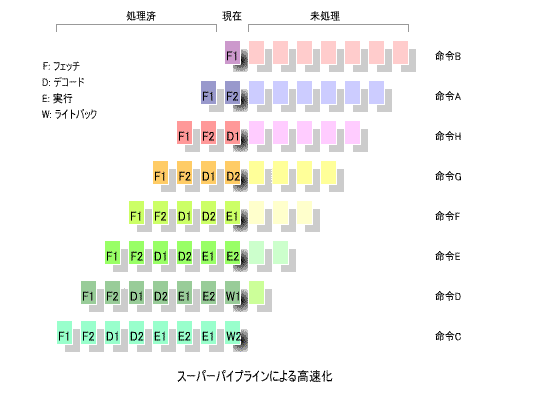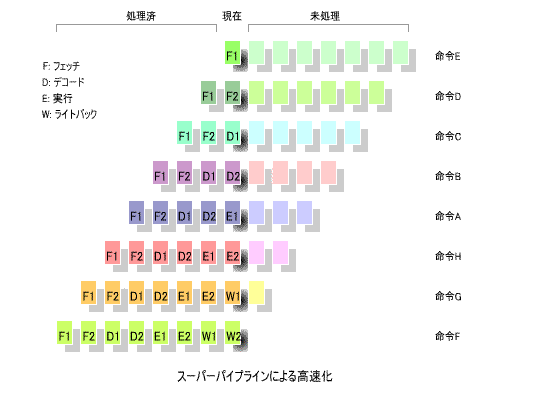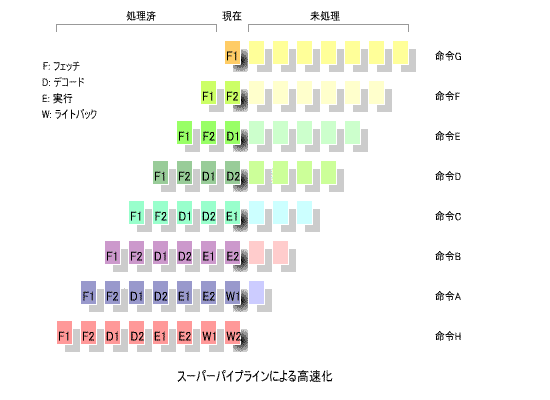
7. スーパーパイプライン方式
-
パイプライン処理は、
「フェッチ」
、
「デコード」
、
「実行」
、
「ライトバック」
の各ステージに
-
専用のハードウェア(回路)を設け、これらをベルトコンベアのように接続することにより、
-
各ステージを実質的に1クロックで処理して、高速化を図る手法でした。
-
-
このパイプライン処理を、さらに高速化する目的で開発されたのが、ここで述べる
-
「スーパーパイプライン方式」
です。
-
-
その原理は極めて単純で、各ステージをより細かく分割するというものです。
-
前の説明を踏襲すれば、4つのステージの仕事を前半と後半に分け、それぞれ2人で
-
分担するというものです。
-
-
下の図に、その原理を示します。
-
この例では、
「フェッチ (F)」
、
「デコード (D)」
、
「実行 (E)」
、
「ライトバック (W)」
の4ステージを
-
それぞれ前半と後半に分け、
「フェッチ (F1, F2)」
、
「デコード (D1, D2)」
、
「実行 (E1, E2)」
、
-
「ライトバック (W1, W2)」
の
8ステージ
に分割しています。1ステージに要する時間が半分に
-
短縮されるので、周波数が2倍のクロックで動作させることができます。
-
-
「パイプラインハザード」
がなければ、実質的に4ステージの場合に比べ、2倍の高速化が
-
実現できることになります。
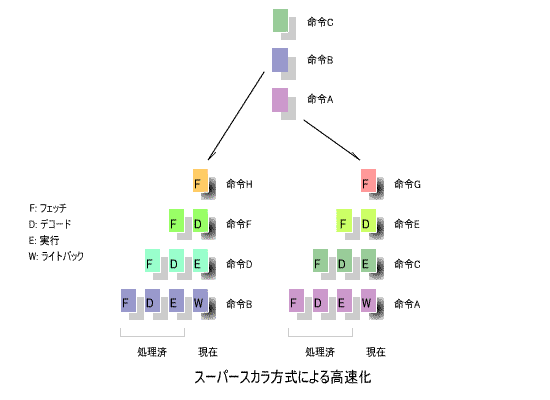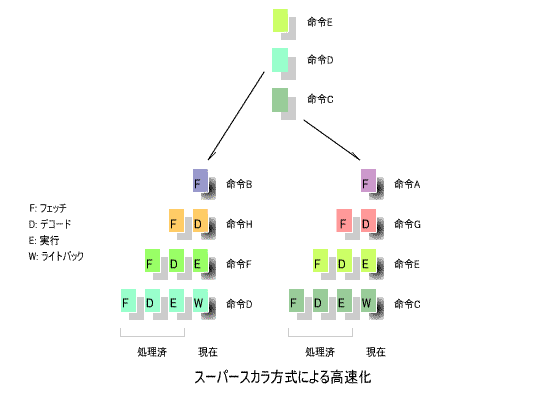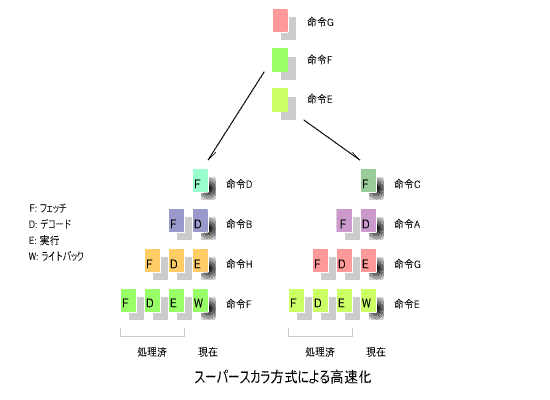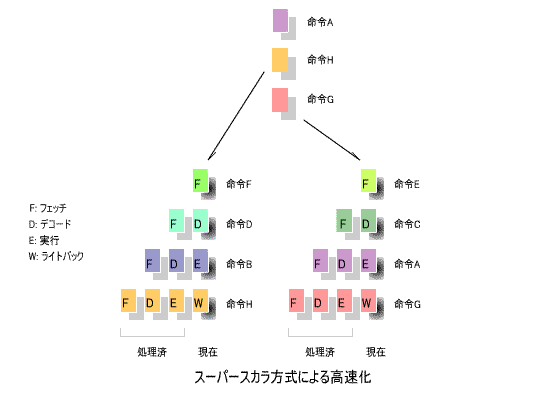
8.スーパースカラ方式
-
「スーパーパイプライン処理」
は、
「フェッチ」
、
「デコード」
、
「実行」
、
「ライトバック」
の各ステージを
-
前半と後半に分け、実質的なステージ数を増やすことにより高速化を図るというものでした。
-
-
このときの
ベルトコンベア
は1台であり、増強した作業者を密に配置するという手法です。
-
しかし、同じように人を増やすにしても、ベルトコンベアを2台以上設置すれば、各ステージの
-
仕事の内容を細かく分割することなく、トータルのアウトプットを2倍以上に向上させることが可能です。
-
-
このような処理の並列化により高速化する手法が、
「スーパースカラ方式」
です。
-
下の図に、その概念を示します。
-
-
この例では、A、B、C、D、E、F、G、Hの各命令を偶数番目と奇数番目に分け、2つの
パイプライン
-
により処理していますが、3つ以上に分割することも可能です。
-
また、たとえば
「フェッチ」
は共通にして、他のステージを複数のパイプラインで処理する方式も
-
用いられています。
-
ここで、質問です。
-
このような
「スーパースカラ方式」
がすべての場合に有効であるというわけではありません。
-
どのようなとき、問題が生じるのでしょうか? 考えてみて下さい。
9.アウト・オブ・オーダー命令発行
-
「スーパースカラ方式」
は、命令をたとえば偶数番と奇数番のように分け、それぞれ別のパイプライン
-
により計算する手法であり、いわゆる
処理を並列化
する1つの手法です。
-
しかし、どのような場合でも高速化できるとは限りません。
-
計算には手順があり、順序が変わると結果が異なってしまうことがあるからです。
-
-
たとえば、レジスタの内容をI/Oの出力ポートに出力してから、その内容を+1する処理を単純に
-
並列化することはできません。
-
順序が入れ替わると、出力ポートに+1された結果が出力されてしまいます。
-
-
また、特定のレジスタやメモリを2つのラインで使用する場合、いわゆる
「資源の競合」
が発生します。
-
このような資源は1つしかないので、これを2つの回路で同時に使用しようとする場合は、どちらか
-
一方を遅らせなければなりません。
-
-
このような処理の並列化を進めるときに、
「アウト・オブ・オーダー命令発行」
という手法が有効であると
-
言われています。
-
この手法は、プログラムに書かれている命令の順序を入れ替えることにより、資源の競合等を防ぎ、
-
「スーパースカラ方式」
の並列性を高める技術です。
-
-
以下、簡単な例を用いて説明しましょう。
-
4つの数字をレジスタに読み込んでそれらの和を計算し、出力用のポートに出力するというプログラムを
-
アセンブラ言語(x86系)を用いて記述すると、次のようになります。
-
以下、簡単に各行の内容について説明します。
-
①
[mov ax, 5]
; axレジスタに値 5を代入する。
-
②
[mov bx, 3]
; bxレジスタに値 3を代入する。
-
③
[mov cx, 2]
; cxレジスタに値 2を代入する。
-
④
[mov dx, 4]
; dxレジスタに値 4を代入する。
-
⑤
[add ax, bx]
; axレジスタとbxレジスタの和を計算し、結果をaxレジスタに代入する。
-
⑥
[add ax, cx]
; axレジスタとcxレジスタの和を計算し、結果をaxレジスタに代入する。
-
⑦
[add ax, dx]
;
axレジスタとdxレジスタの和を計算し、結果をaxレジスタに代入する。
-
⑧
[mov dx, PORT]
; dxレジスタに出力するポートのアドレス(PORT)を設定する。
-
⑨
[out dx, ax]
; dxで指定した出力ポートに、axレジスタの内容を出力する。
-
-
ここで、
ax
、
bx
、
cx
、
dx
はそれぞれ独立したレジスタを表しており、
PORT
は出力するポート番号に
-
対応します。なお、x86系のCPUの場合、各レジスタの機能は必ずしも一定ではありません。
-
(例えば、
out命令
の場合、
dx
に出力ポート番号、
ax
に出力するデータを指定します。)
-
-
ここで
⑤と⑥
を見て下さい。いずれも、
axレジスタ
を使用しており、
資源の競合
により、これらを
-
同時に使用することはできません。
-
同様に、
-
-
・
⑥と⑦
-
・
⑦と⑧
-
・
⑧と⑨
-
-
が、競合関係にあります。
-
このとき、並列度が2の
「スーパースカラ方式」
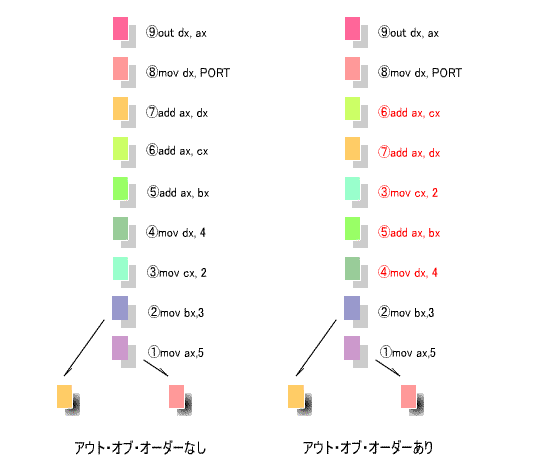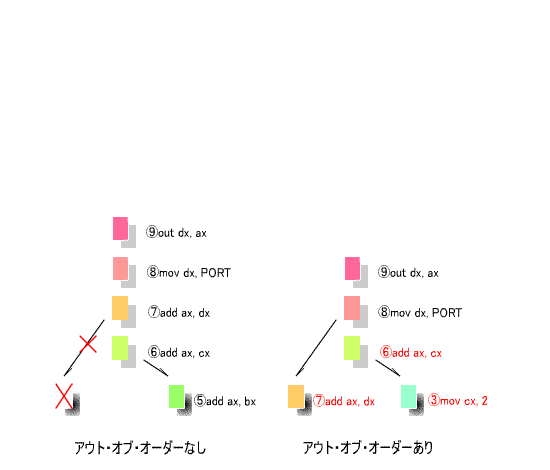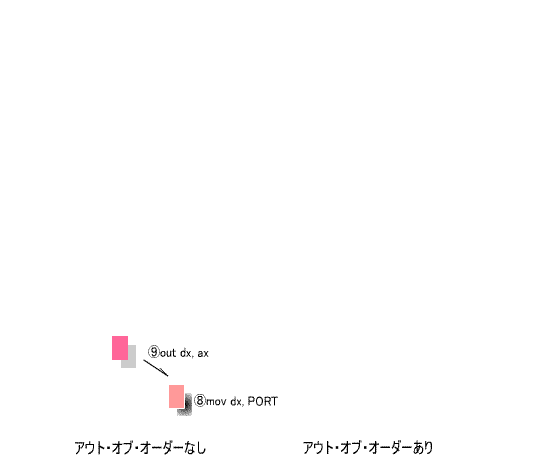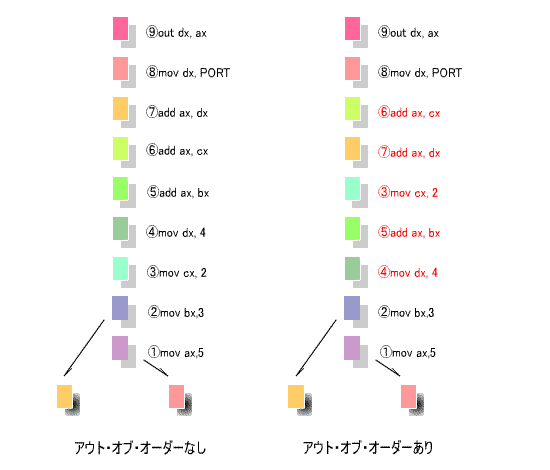
で素直に計算すると、図の左のようになります。
-
すなわち、
①と②
、そして
③と④
は独立に実行しても
「資源の競合」
は発生しないので、それぞれ
-
1クロックで並列に処理できますが、
⑤~⑨
は、axレジスタとdxレジスタのいずれかが競合する
-
ので並列化できず、
1命令
を
1クロック
で処理することになります。
-
-
ここで、命令の
③~⑦
の順序を図の右のように入れ替えます。なお、このような入れ替えを行って
-
も、演算結果には影響しないことは明らかです。
-
すなわち、
-
-
・
④と⑤
-
・
③と⑦
-
・
⑥と⑧
-
-
を同時に実行しても、
「資源の競合」
は発生しません。
-
このように、演算結果が変わらないように、命令を実行する順序を入れ替えることにより、
-
「スーパースカラ方式」
の
並列度
を向上させる手法を、
「アウト・オブ・オーダー命令発行」
と
-
言います。
-
-
下の例では、
「アウト・オブ・オーダーなし」
の場合
7クロック
必要でしたが、この手法により、
-
5クロック
に短縮化することができました。
-
-
このような
「
アウト・オブ・オーダー命令発行
」
は、高性能のCPUに必ずといってよいほど、導入されている
-
技術です。その原理・動作について、十分理解して下さい。
-
10.レジスタ・リネーミング方式
-
複数のレジスタに適当な名前を付け、これらを必要に応じて入れ替えることにより、資源の競合が発生する確率を下げ、
-
「スーパースカラ方式」
の
並列度
を向上させる手法です。
-
しかし、x86のようにレジスタの機能が均一でないCPUには向いていません。
-
-
11.まとめ
-
このコンテンツでは、CPUを高速化するいくつかの手法について解説しました。
-
自分が使用しているパソコンのCPUについて、「スーパーパイプライン方式」の段数や「スーパースカラ方式」の
-
並列度などについて、調べてみることをお勧めします。
-
-
さらに詳しい内容については、教科書や雑誌等で調べて下さい。