PSM3Dの部屋の別室(コンパイラの部屋)

更新日:2010/04/4
リンクは自由にしていただいてかまいませんが、なるべくmototomのページのHOMEに張っていただけますようにお願いします。
HOME以外のアドレスは変更になる可能性があります
ホームへ戻る
【PSM3D用クロスCコンパイラ開発中間たぶん最終まとめ】
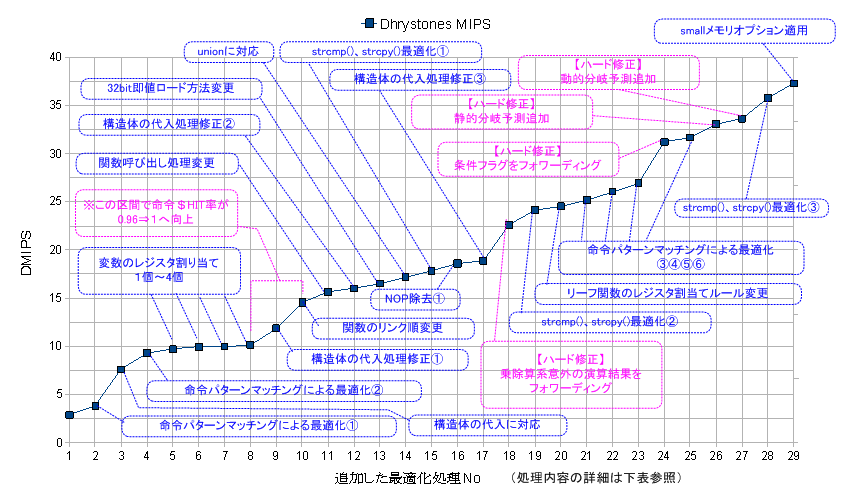
Dhrystone2.1をようやくコンパイル出来るようになった(※1)ので、性能を計測してみましたが、最適化まったく無しだと悲惨な結果に。。。
あれこれと手を加えて、ついに37.05DMIPS(0.529DMIPS/MHz)までたどり着きました。
コンパイラ初挑戦ということで、とにかく完成させることを最優先で作った為、抽象度の高いレベルでの最適化が出来るように考慮してません。
ほぼ覗き窓最適化しか手がない状態です。ハードにもいろいろ手を加えて、それでもどうにか 37.05DMIPSまでたどり着きました。
次回作では、もっといろいろ出来るようにしたいと思いつつ、あんまり凝り過ぎると完成前に挫折しそうで、さじ加減が難しい所です。
スタート時点の2.88DMIPSから、いかにして、37.05DMIPSまでたどり着いたかは、下記に簡単にまとめてます。
コンパイラの最適化処理改良やライブラリ関数(strcpy()とstrcmp())定義の見直しによる小刻みな性能向上に比べて、単発の効果としては、
フォワーディング回路追加(ハード修正)の効果が大きかった事がわかります。又、No9からNo10にかけては、関数のリンク順を変えて
命令キャッシュのHit率を0.99から1に向上させることで、約20%も性能が上がっています。現状のDDRメモリI/Fのレイテンシが如何に大きい
かがわかります。こういった、もろもろのデータを、今後に生かしていきたいと思います。
※1:Dhrystone2.1のソースを一部修正してコンパイルが通るようにしています。例えば、関数の宣言をK&R風からANSI風にしたり、
配列をtypedef出来ないので、例えば、”typedef char Str_30 [31];”と定義して、”Str_30 Str_1_Loc;”と宣言されている所、
を単に、”char Str_1_Loc[31];”と書き換えたりです。malloc()などは計測用ループの外で使われているだけなので、単に
固定領域いを割り当てるだけにしています。
※2:DMIPS=DhrystoneMIPS=VAX MIPS
追加した最適化処理(ハード修正含む)とDhrystoneMIPS値のグラフ
追加した最適化処理の内容と各種計測結果の表
|
No |
追加した最適化処理の内容 |
DMIPS |
DMIPS |
性能 |
CPI |
I$ |
IBUS |
D$ |
DBUS |
コードサイズ(※5) |
|
1 |
最適化無し。 脅威の低性能! orz | 2.88 | 0.041 | - | 2.13 | 0.99 | 1.29 | 0.95 | 1.07 | 18384 |
|
2 |
No1に対して、式単位での低レベル最適化を追加。 (例) ADD_I, R1, FP, FpOffsetOf(a) //変数aのアドレス計算 LDW_I, R1, R1, 0 //変数aをR1へロード を LDW_I, R1, FP, FpOffsetOf(a) //変数aをR1へロード へ変換など、簡単なパターンマッチングで何とかなる部分だけ最適化 ちょっとだけ早くなったが、まだ全然ダメ・・・ |
3.80 | 0.054 | 1.319 | 2.14 | 0.99 | 1.33 | 0.95 | 1.08 | 15748 |
|
3 |
No2に加えて、構造体の代入を追加。
Dhrystoneでは、コンパイラが構造体の代入に対応できない場合は、1バイトずつループを回して構造体のコピーをする関数が呼ばれるから、ここがボトルネックと予想。 思ってたより性能が伸びた。少しテンションが上がった。 |
7.92 | 0.109 | 2.005 | 2.7 | 0.97 | 1.82 | 0.97 | 1.06 | 16056 |
|
4 |
No3に加えて、分岐の最適化を追加。 最適化後 |
9.29 | 0.133 | 1.219 | 2.65 | 0.97 | 1.62 | 0.95 | 1.15 | 15052 |
|
5 |
No4に加えて、ローカル変数&引数をレジスタへ配置する最適化を追加。 ※No1〜4では、全ての変数はメモリ上に置いていた。 ※メモリへ配置する変数は、最も参照回数が多いと推定されるもの(ループ内で参照など)から順に決定 レジスタへ配置する変数=1個。 ちょっとだけ効果あり。まあ、1個じゃこんなもんか。 |
9.72 | 0.139 | 1.046 | 2.75 | 0.97 | 1.88 | 0.95 | 1.17 | 15200 |
|
6 |
レジスタへ配置する変数=2個。 | 9.97 | 0.142 | 1.026 | 2.92 | 0.96 | 2.07 | 0.94 | 1.14 | 14964 |
|
7 |
レジスタへ配置する変数=3個。 | 9.99 | 0.143 | 1.002 | 2.88 | 0.96 | 2.08 | 0.94 | 1.14 | 14860 |
|
8 |
レジスタへ配置する変数=4個。 この後、5個以上についても試して見たが、4個より、5個が少しだけまし程度。6個にもトライしたが、暴走してしまった。。。スクラッチレジスタが不足した場合にはスタックを使って演算する処理を入れているが、最低でも4個のスクラッチレジスタがないとうまく動作しないアルゴリズムになっていた。レジスタへ割り当てる変数を6個にすると、スクラッチレジスタ数が3個しか残らないので処理が破たんしたようだ。よって、以降は、スクラッチレジスタの余裕を考慮して、レジスタへ配置する変数=4個で固定して評価を進める。よく、コンパイラの立場からみた場合、汎用レジスタの数は多いほどよいと言われるけど、まさに実感。 |
10.14 | 0.145 | 1.015 | 2.85 | 0.96 | 2.07 | 0.93 | 1.07 | 14804 |
|
9 |
No8ベースで、構造体のコピーをループ化(これまでは、LD/ST命令を構造体サイズ分生成していた) 命令キャッシュのヒット率が向上。もう少しでメインループが全部キャッシュに載る。 |
11.86 | 0.169 | 1.170 | 2.15 | 0.99 | 1.03 | 0.91 | 1.45 | 14368 |
|
10 |
No9に加えて、命令$のヒット率が上がるように、dhrystoneのソースに追加していた文字列表示用関数の定義位置を変更。 dhrystoneのメインループ全体が命令キャッシュに載るようになり、命令キャッシュのヒット率がやっと1になった。おかげで一気に3DMIPS弱向上。 |
14.53 | 0.208 | 1.225 | 1.77 | 1 | 1 | 0.92 | 1.29 | 14368 |
|
11 |
No10に加えて、関数呼び出し時に今まで不要なレジスタまで退避していたのを、必要な分だけ退避するように修正。 | 15.67 | 0.224 | 1.078 | 1.71 | 1 | 1 | 0.95 | 1.06 | 13904 |
|
12 |
No11から、構造体のコピーを非ループ化(LD/ST命令を構造体サイズ分生成…No9の対応を元に戻した) 約2%性能Upした。結局、No9の時は構造体コピーをループ化して本当は遅くなったが、代わりに命令キャッシュのHit率が上がった為に、ループで遅くなった分をカバーして、トータルで性能が上がったのだろう。一方で、データキャッシュのHit率が低くなっている。32ビット即値はプログラム領域にある即値データをPC相対でロードしていて、この時当然データキャッシュにフィルされるので、キャッシュラインの競合が出ていると推測。少なくとも、静的に確保された変数領域のサイズは、4Kバイト以下なので、こう考えるのが妥当だろう。 |
16.01 | 0.229 | 1.022 | 1.9 | 1 | 1 | 0.92 | 1.37 | 14372 |
|
13 |
No12に加えて、32ビット即値のロードをPC相対LDから、MOVH_IとOR_Iの組み合わせでロードするように変更。 コードサイズは増えてしまったが、データキャッシュのヒット率が上がり、約3%性能Upした。 |
16.51 | 0.236 | 1.031 | 1.79 | 1 | 1 | 0.94 | 1.09 | 15736 |
|
14 |
No13をベースに、unionに対応。 No13までは、unionに未対応だったので、元のソースでは構造体(struct record)のメンバにunionが定義されていたのを、structに置き換えていた。 このせいで、struct recordのサイズがほぼ倍になってしまっていて、しかもDhrystoneのメインループ内でこの構造体をコピーしてるので、性能が落ちていた。約4%性能Upで、17DMIPS超え!。20DMIPSにだいぶ近づきました。 |
17.15 | 0.245 | 1.039 | 1.77 | 1 | 1 | 0.97 | 1.03 | 15500 |
|
15 |
strcpy()のループ内の定義を下記のように変えてみた。 (変更前)*dst++ = *src++; ⇒ (変更後)*dst = *src; ++dst; ++src; 後置++/--は最適化が難しいので、記述を分けた方が最適化のパターンマッチングにはまりやすい。 |
17.84 | 0.255 | 1.040 | 1.79 | 1 | 1 | 0.97 | 1.03 | 15492 |
|
16 |
関数単位での最適化の最後に、NOP除去処理を追加。 最適化の結果、命令を削除した所の一部に、処理の都合上NOPを残していた所があったので、それを削除。ループ内にNOPが残っている所もあったので、以外と効果があった。 |
18.57 | 0.265 | 1.041 | 1.85 | 1 | 1 | 0.97 | 1.03 | 14612 |
|
17 |
No16に加えて、構造体代入をさらに最適化。又、MOVR命令でレジスタ値をコピーしている所で、コピーを削減出来る所を探して削減する処理を追加 | 18.89 | 0.270 | 1.017 | 1.83 | 1 | 1 | 0.97 | 1.03 | 15172 |
|
18 |
【ハード修正】コンパイラはNo17
のままで、未使用の命令(ベースレジスタのプレ/ポスト更新付きのLD/ST命令・他)の回路を削除して、加減算と論理演算結果のみフォワーディング回路を追加 それなりの効果あり。(約2割Up) 意外だったのは、回路規模が4634スライス⇒4232スライスに下がった事と、速度が落ちなかった事。論理合成の最適化のツボにはまったか? |
22.60 | 0.323 | 1.196 | 1.53 | 1 | 1 | 0.97 | 1.03 | 15172 |
|
19 |
No18に加えて、strcpy()とstrcmp()の定義を修正 とにかく、ストールが発生しにくい実行順序にしてみたら、それなりの効果があった。ライブラリ関数はコンパイラの範疇なので、反則ではないはず。 |
24.15 | 0.345 | 1.069 | 1.48 | 1 | 1 | 0.97 | 1.03 | 15232 |
|
20 |
No19に加えて、リーフ関数の場合は、呼び出した下位関数がスクラッチレジスタを破壊する心配が無いので、なるべくスクラッチレジスタに変数を割り当てて、関数入り口と出口のレジスタ退避&復帰回数を削減。わずかだが効果あった。 | 24.53 | 0.350 | 1.016 | 1.52 | 1 | 1 | 0.96 | 1.04 | 14988 |
|
21 |
No20に加えて、JP命令の飛び先が無条件JP命令の場合は、一個目のJP命令の飛び先を、無条件JP命令の飛び先へ変更する最適化を追加(No20以前の最適化の結果、このような変なコードが時々出現する) [最適化後] |
25.18 | 0.360 | 1.026 | 1.51 | 1 | 1 | 0.96 | 1.04 | 14988 |
|
22 |
No21に加えて、関数呼び出しをレジスタ間接から、PC相対即値指定に変更可能なケースは、PC相対即値指定に変更するように最適化 [最適化後] |
26.03 | 0.372 | 1.034 | 1.51 | 1 | 1 | 0.96 | 1.05 | 13326 |
|
23 |
No22に加えて、以下のような冗長なパターンを最適化
[最適化後] |
26.94 | 0.385 | 1.035 | 1.46 | 1 | 1 | 0.96 | 1.05 | 13220 |
|
24 |
【ハード修正】コンパイラはNo23 のままで、条件フラグのフォワーディング回路を追加 約16%性能向上。効果大。30DMIPS超え達成! 回路規模は、4232スライス⇒4337スライスと増加。思ってたより回路規模が増えた。論理合成の最適化のツボからはずれた? |
31.23 | 0.446 | 1.159 | 1.27 | 1 | 1 | 0.96 | 1.04 | 13220 |
|
25 |
No24に加えて、2倍、4倍の掛け算を、それぞれ自身の加算1回、自身加算2回へ変更 [最適化後] |
31.65 | 0.452 | 1.013 | 1.23 | 1 | 1 | 0.96 | 1.05 | 13260 |
|
26 |
【ハード修正】コンパイラはNo25
のままで、Dキャッシュドレイン命令の回路を削除するのを忘れたので削除し、静的分岐予測回路を実装。 効果あるにはあったが、思ってたほどではなかった。(約4%) 3段パイプラインで、分岐ペナルティは、もともと1サイクルなので、こんなものだろう。 今まで「分岐予測は難しそう」という思いがあって、深く考えることなく実装を諦めていたが、いざやり始めてみると1時間ほどで出来てしまった。 食わず嫌いでございました。 遅延分岐を採用していなかったのも実装を楽にしてくれたように思う。 回路規模は4337スライス⇒4213スライスに低下。削除したDキャッシュドレイン命令の回路は、ごくわずかなので、また論理合成の最適化のツボにはまった? |
33.05 | 0.472 | 1.044 | 1.18 | 1 | 1 | 0.96 | 1.05 | 13260 |
|
27 |
【ハード修正】コンパイラはNo25 のままで、動的分岐予測回路を追加。具体的には、Spartan3EのブロックRAMは、1個で36bit幅まで使えるので、命令キャッシュのビット幅を32bitから35ビットに広げて、ここに、分岐予測対象の命令かどうかを示すフラグと、2bitの飽和カウンタを追加し、分岐した/しないで、カウンタを増減。カウンタ値が2以上だと、分岐する側へ予測する。 静的分岐予測と違い、さすがにRTL修正に手間がかかったが、得られた効果は、静的分岐予測の効果に上乗せ2%未満。3段パイプラインのCPUで分岐予測に過大な期待したらダメですね。でも、コンパイラによる最適化が手詰まりの状態から、2DMIPS近く性能を上乗せ(対No25)出来たのはうれしい。ちなみに、回路規模は、4213スライス⇒4340スライスへと増え、まあ順当。 |
33.63 | 0.480 | 1.018 | 1.16 | 1 | 1 | 0.96 | 1.04 | 13260 |
|
28 |
気がつけば、No27で、0.48DMIPS/MHzまで来てました。こうなってくると、なんとかして0.5DMIPS/MHzを超えたくなります。 そこで、strcpy()と、strcmp()に対して、今まであえて避けてきた、人手によるアセンブラレベルでの最適化を実施(ライブラリ関数はコンパイラ側の範疇なので反則ではないはず)しました。それぞれの関数で、ループ内の命令数を1個削減。 ついに、0.5DMIPS/MHz超え達成! あータバコがうめー゚゚゚゚゚-y(^。^)。 |
35.52 | 0.507 | 1.056 | 1.15 | 1 | 1 | 0.96 | 1.04 | 13260 |
|
29 |
とどめに、smallメモリモードでビルド。(-sオプションを付ければ、静的変数の総サイズが32Kバイトに制限されるのと引き換えにグローバル変数の参照を下の例のように高速化) [-sオプション有りの場合のGlobal変数を参照するコード] |
37.05 | 0.529 | 1.043 | 1.15 | 1 | 1 | 0.97 | 1.04 | 12380 |
※3:命令バスアクセスの平均レイテンシ、キャッシュヒット時=1(=ウェイト0)。
※4:データバスアクセスの平均レイテンシ、キャッシュヒット時=1(=ウェイト0)。
※5:画面表示も含むプログラム全体のコードサイズ(単位:バイト)
このページに関するご意見などございましたら mototom@xsj.biglobe.ne.jp までお願いします。
ホームへ戻る