XoLに関する研究一覧
XoLでは,あくまで手法の応用を主眼に置き,
最適性よりも,より少ない試行錯誤回数での合理性の保証を目指す.
また,目的達成時に与えられる「報酬信号群」,および,
制約違反時に与えられる「罰信号群」間の優先順位のみを教師信号とし,
報酬および罰の値の設計は,それが容易に行える場合以外は行わない.
これら独自の観点を導入することにより,これまでの強化学習とは異なった,
手法の応用を主眼に置いた新たな接近法が誕生することになる.(図1参照)

図1:XoLと強化学習との比較
2013年3月末現在,XoLに関する研究として図2のような研究が存在する.
なお,Profit Sharingに関する理論的研究については
こちらをご参照ください.
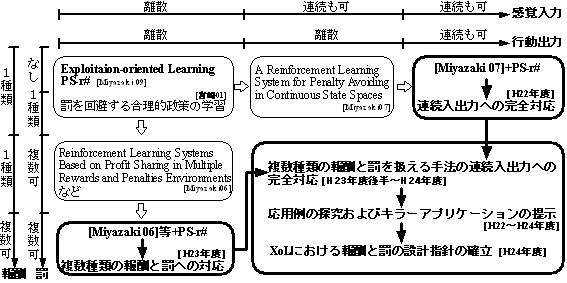
図2:XoLに関する研究の発展
-
宮崎和光,山村雅幸,小林重信:強化学習における報酬割当ての理論的考察,人工知能学会誌,Vol.9, No.4, pp.580-587 (1994).
宮崎和光,木村元,小林重信:Profit Sharingに基づく強化学習の理論と応用,人工知能学会誌,Vol.14, No.5, pp.800-807 (1999).
- 宮崎和光,荒井幸代,小林重信,
POMDPs環境下での決定的政策の学習,
人工知能学会誌, Vol.14, No.1, pp.148-156 (1999).
-
宮崎和光,荒井幸代,小林重信:Profit Sharingを用いたマルチエージェント強化学習における 報酬配分の理論的考察,
人工知能学会誌, Vol.14, No.6, pp.1156-1164 (1999).
- Miyazaki, K. and Kobayashi, S.,
Rationality of Reward Sharing
in Multi-agent Reinforcement Learning,
New Generation Computing,
Vol.19, No.2, pp.157-172 (2001).
- 宮崎和光,坪井創吾,小林重信,
罰を回避する合理的政策の学習,
人工知能学会論文誌, Vol.16, No.2, pp.185-192 (2001).
- 宮崎和光,坪井創吾,小林重信,
罰回避政策形成アルゴリズムの改良とオセロゲームへの応用,
人工知能学論文誌, Vol.17, No.5, pp.548-556 (2002).
-
宮崎和光,小林重信:Profit Sharingの不完全知覚環境下への拡張: PS-r*の提案と評価,
人工知能学会論文誌, Vol.18, No.5, pp.286-296 (2003).
11 pages, pdf file, 2reF-2A8.pdf (328,483 bytes)
-->
- Miyazaki, K., Tsuboi, S. and Kobayashi, S.,
Development of a reinforcement learning system to play Othello,
Artificial Life and Robotics, Vol.7, No.4, pp.177-181 (2004).
-
宮崎和光,木村元,小林重信:合理的政策形成アルゴリズムの連続値入力への拡張,
人工知能学会論文誌, Vol.22, No.3, pp.332-341 (2007).
- Miyazaki, K. and Kobayashi, S.,
A Reinforcement Learning System for Penalty Avoiding in
Continuous State Spaces,
Journal of Advanced Computational Intelligence and Intelligent
Informatics,
Vol.11, No.6, pp.668-676 (2007).
- Watanabe, T., Miyazaki, K. and Kobayashi, H.,
A New Improved Penalty Avoiding Rational Policy Making Algorithm
for Keepaway with Continuous State Spaces,
Journal of Advanced Computational Intelligence and Intelligent
Informatics,
Vol.13, No.6, pp.675-682 (2009).
- Miyazaki, K. and Kobayashi, S.,
Exploitation-oriented Learning PS-r#,
Journal of Advanced Computational Intelligence and Intelligent
Informatics,
Vol.13, No.6, pp.624-630 (2009).
- Miyazaki, K.,
Proposal of the Continuous-Valued Penalty Avoiding Rational Policy Making Algorithm,
Journal of Advanced Computational Intelligence and Intelligent Informatics,
Vol.16, No.2, pp.183-190 (2012).
- Kuroda, S., Miyazaki, K. and Kobayashi, S.,
Introduction of Fixed Mode States into Online Reinforcement Learning with Penalty and Reward
and Its Application to Waist Trajectory Generation of Biped Robot,
Journal of Advanced Computational Intelligence and Intelligent
Informatics,
Vol.16, No.6, pp.758-768 (2012).
- Miyazaki, K.,
Proposal of an Exploitation-oriented Learning Method on Multiple Rewards and Penalties \
Environments and the Design Guideline,
Special Issue: Advances in Internet Technologies and Applications,
Journal of Computers, to appear.