近年,深海や宇宙空間などの人の手が及びにくい未知環境を開拓するための
一手法として自律型ロボットが注目されつつある.
一般にそのような未知環境においては,手取り足取り正解を教えてくれるような
教師を想定することはできない.
そのためロボットは試行錯誤を繰り返し,
結果的に良かったか悪かったかという情報のみから学習しなければならない.
ここではそのような情報を総称して報酬と呼ぶ.
強化学習とは,この報酬という特別な入力を手がかりに環境に適応した
行動決定戦略を追求する教師なし機械学習である.
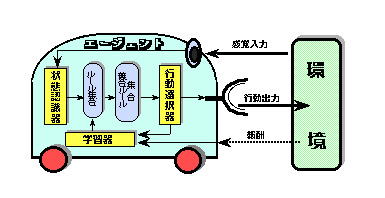
ここで,未知なる環境に置かれた下図のようなロボットを考える.
ロボットは環境からの感覚入力に対して,行動を選択し,実行に移す.
一連の行動に対して,環境から報酬が与えられる.
一般に,時間は認識-行動サイクルを1単位として離散化される.
感覚入力は離散的な属性-値ベクトルとして与えられ,
行動は離散的なバリエーションの中から選ばれる.
感覚入力に対して実行可能な行動はルールとして記述され,
各感覚入力に対し選択すべきルールを与える関数は政策と呼ばれる.
強化学習の目的は,出来るだけ少ない行動選択回数で,
出来るだけ多くの報酬を獲得することにある.